导言:接上篇经典Gan Loss原理以及其实现,本篇深入探讨一下各种GanLoss。
经典GAN loss缺点:

在经典GAN LOSS中Disciminator是一个Binery Classifier, 对于图中所示的两种分布,二分类判别器给出的两者loss是相同的,但是实际上的损失应该要小一点(距离近).
二分类判别器给出的两者loss是相同的
解释:当Disciminator足够强时,其最后一层的output 经过softmax得到是属于class 1 和class 2的概率。分别是1(0),0(1).这样每一次都是log2(js div对于不重合的分布距离大小)
LS Gan:
将二分discriminator从分类损失转为回归损失即可。1
2
3
4
5
6
7
8
9
10...
# !!! Minimizes MSE instead of BCE
adversarial_loss = torch.nn.MSELoss()
...
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
...
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = 0.5 * (real_loss + fake_loss)
...
WGan:
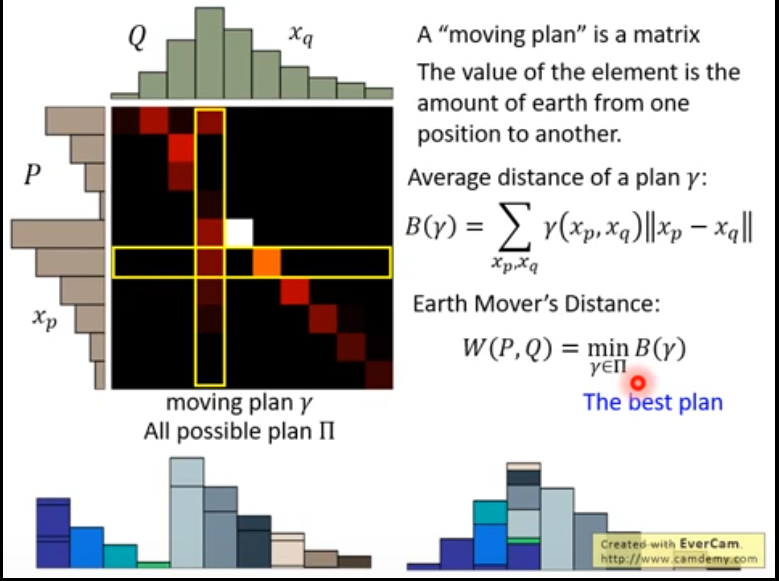
一个热力图对应了一个moving plan,将转移到分布上。实际WGAN loss需要解一个最优化问题找到最优的来使地B最小。
公式的推导李宏毅老师没有讲解,本篇也不赘述。直接给出其形式:

Weight clipping
对于Dis中每一个参数其大小需要平滑变换,不能变化太大,太大的或太小进行裁剪。
1 | ... |
WGAN-GP
1 |
|