实验记录:
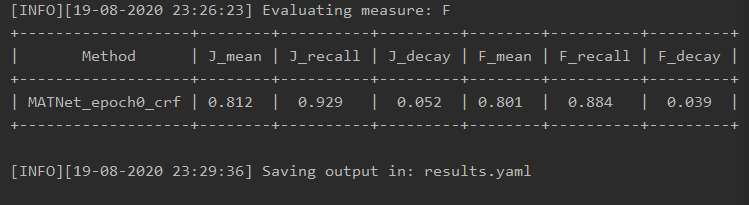
T0819:对作者提供的模型进行test,得到结果,使用crf对其进行后处理。使用std davis-python代码测试,其结果为:
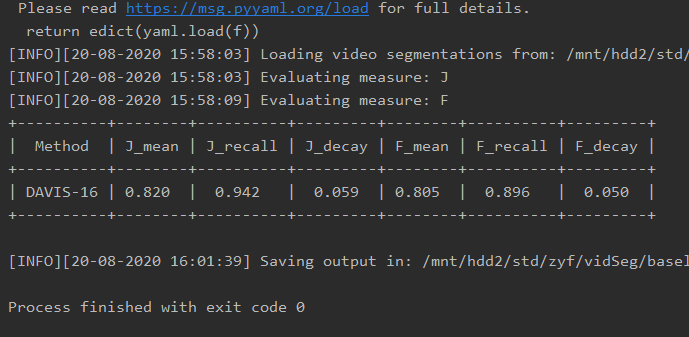
对作者提供的结果,使用std davis-python代码进行测试,其结果为:
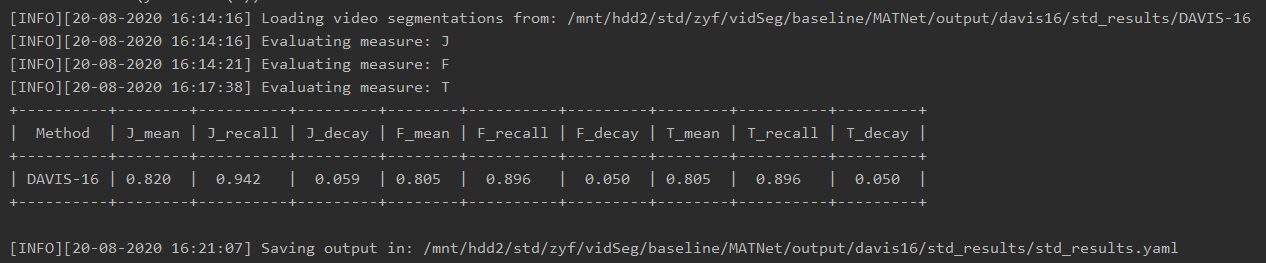
实验pipeline:
- 使用pwc计算光流.
- 使用hed计算边缘+质信度,这个是用过网络计算的.
- Paper使用.m代码通过gt-mask计算边缘. 我使用的vid2vid中的边缘检测代码进行计算。保存为`./3rfparty/seg2edges.py文件。
- 使用train`_MATMet.py文件。将当前帧光流(应该是前向光流)以及当前帧输入进网络。得到4张bdry图片和一样mask图片。计算分类损失(mask以及bdry)进行优化。
- 使用
test_MATNet.py文件。输出结果会比实际少一帧,因为光流只有N-1帧。 - 使用
apply_densecrf_davis.py文件对输出结果进行post-processing。获得最终的二值化mask。 - 使用std davis-python对输出结果进行评估。
基于baseline进行修改创造
baseline优点,以及其他论文优缺点总结:
早期方法:
Early nonlearning methods typically address this using handcrafted features, e.g. motion boundary (Papazoglou and Ferrari 2013), saliency (Wang, Shen, and Porikli 2015) and point trajectories (Ochs, Malik, and Brox 2013).
zero-shot solution:
[intro][zero-shot solution][RVOS] 1903.05612使用RNN and ConvLSTM to leverage the temporal feature, think at different resolutions. 同样也使用mask from previous frame as one additional channel to predict the mask of current frame.(this stratygy is design for one-shot VOS task)“The inclusion of the mask from the previous frame is especially designed for the one-shot VOS task, where the first frame masks are given. “
不同是,使用用了instance 之间的关系,以及muilty scale.
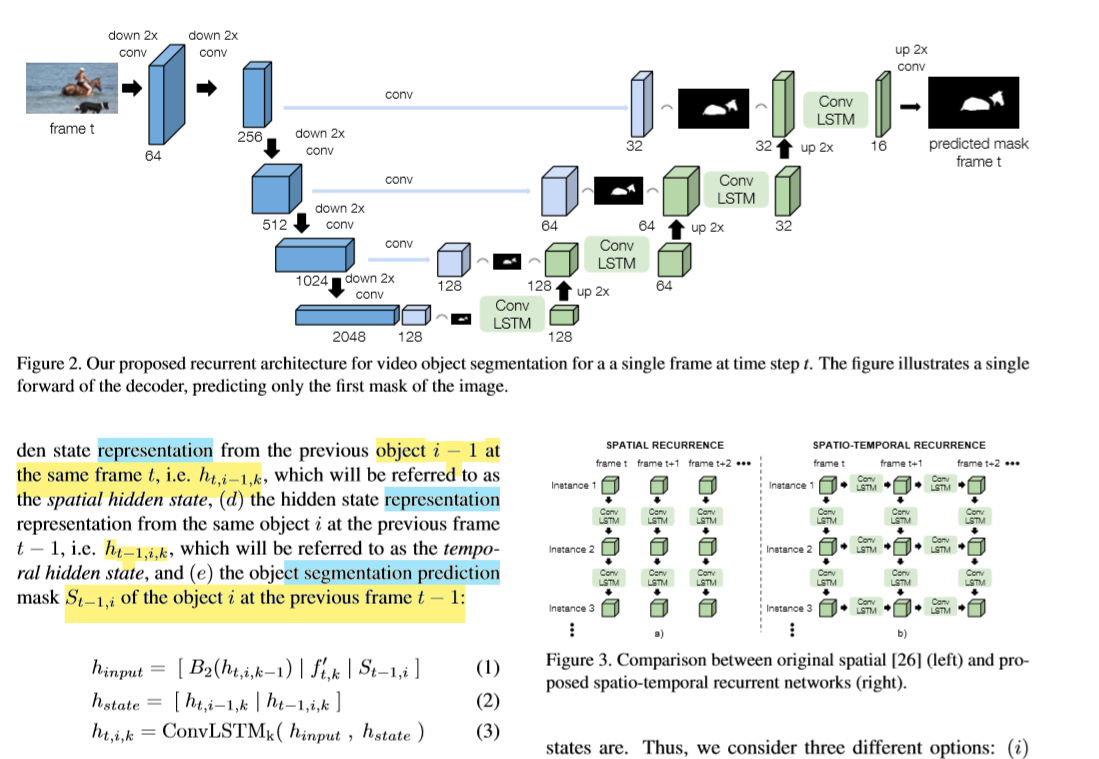
RVOS 利用纵横ConvLSTM特征 [AGNN]Wang_Zero-Shot_Video_Object_Segmentation_via_Attentive_Graph_Neural_Networks_ICCV_2019_paper
通过在大量数据集下学习,然后adapt to the test video without any annotations.
this paper builds a fully connected graph to efficiently represent frames as nodes, and relations between arbitrary frame pairs as edges
AGNN intra-attention(内部) 以及 inter-attention(内间)
one-shot solution:
[OSVOS]Caelles_One-Shot_Video_Object_CVPR_2017_paper通过先在大数据集中学习一个模型,根据video的第一帧来进行fine-tune学习。
优点:
缺点:每一个视频需要单独fine-tune一个。[MaskTrack] 1612.02646将前一帧mask与当前帧同时输入网络进行预测当前帧mask。对mask进行多种变换增强鲁棒性。use the predicted masks in the previous frames as guidance for next frames
基于motion to appearence aspects.
[Mp-Net] 1612.07217直接map the flow to the corresponding segmentation mask.[MaskTrack] 1612.02646baseline作者将其归为此类不对。[SFL] SegFlow 1709.06750同时预测flow以及seg,使得在预测flow的同时用flow的特征去cue seg模块提取seg特征。[FSEG] Fusionseg Learning 1701.05384这篇是将Flow +RGB组合进行seg。但是flow 与RGB同等treat.[MoNet] Xiao_MoNet_Deep_Motion_CVPR_2018_papertwo-stream 形式,内嵌了FlowNet, 同时没有将flow与RGB特征同等对待,将Motion 作为Cues进行seg[intro][Li]Siyang_Li_Unsupervised_Video_Object_ECCV_2018_paper,与previous不同的是没有使用dual-branch去同时处理RGB,flow信息,而是提取appearance feature得到objectness,并且基于flow, 构建embedding graph,基于bilateral network (BNN) propagated the graph to finding regions that have similar motion patterns with low-objectness regions(背景)[Mp-Net] 1612.07217单纯的寻找了一个flow 到seg mask 的map model.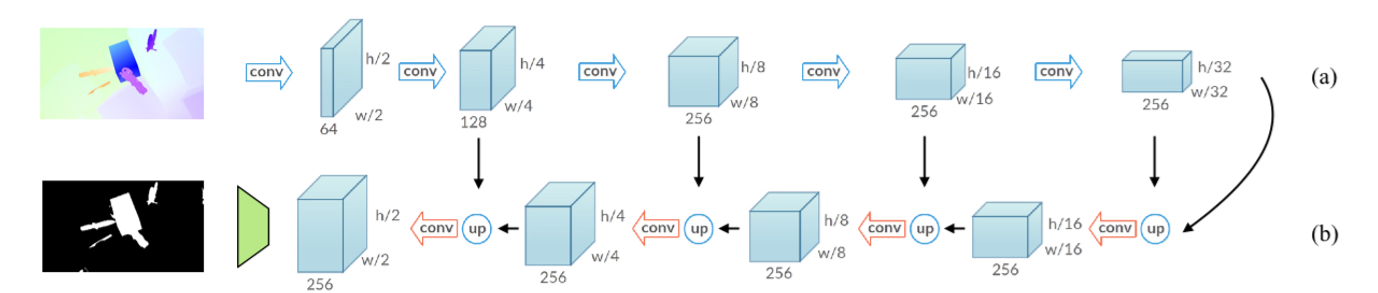
MPNet
这些都只考虑了single scale and ignoring the critical hierarchical structure.
Baseline缺点:
- 基于光流(Motion-Attentive), 光流帧数不同导致输出mask的帧数缺少了最后一帧。
- 前期数据准备较多。flow, hed, edge.
- 对于时序建模只是使用了flow作为cue,其本质还是predict object segmentations at each frame independently. 认为修改为blob(t,t-1)作为输入会更好。
分类:
One-Shot and Zero-Shot VOS
One-shot learning is understood as making use of a single annotated frame (often the first frame of the sequence) to estimate the remaining frames segmentation in the sequence. On the other hand, zero-shot or unsupervised learning is understood as building models that do not need an initialization to generate segmentation masks of objects in the video sequence.
Use Temporal or Not
Aim to model the temporal dimension of an object segmentation through a video sequence, and those without temporal modeling that predict object segmentations at each frame independently.
T-0829
model: model2; bs: 1; model_name: 3tMATNet; lr:1e-3 le_cnn 1e-4; loss: loss = mask_loss + 0.2 * bdry_loss: 失败
model: model2; bs: 1; model_name: 3tMATNet2; lr:1e-3 le_cnn 1e-4; loss: loss = mask_loss + 0.1 * bdry_loss: 失败
model: model2; bs: 1; model_name: 3tMATNetlr; lr:1e-4 le_cnn 1e-4; stratgy:ADAM; loss: loss = mask_loss + 0.05 * bdry_loss:
model: model3; bs: 3(three gpu); model_name: frMATNet; lr:1e-3 le_cnn 1e-4; loss: loss = mask_loss + 0.2 bdry_loss *work
model: model4; bs: 2; model_name: MATNetEpoch100(与baseline测试名称重了,以时间区分,早得是bsl); lr:1e-3 le_cnn 1e-4; loss: loss = mask_loss + 0.2 bdry_loss *work 测试效果没有bsl高
model: model4; bs: 2; model_name: MATNetmodel4; lr:1e-3 le_cnn 1e-4; loss: loss = mask_loss + 0.2 * bdry_loss 修改了decoder得refine
model: model4; bs: 2; model_name: model4bdlossup; lr:1e-3 le_cnn 1e-4; loss: loss = mask_loss + 0.3 * bdry_loss