T20190704:
1.使用pip3 换源:
pip3 install opencv-python —user -i https://pypi.tuna.tsinghua.edu.cn/simple/
ubuntu中python site-package 的位置:
/home/joey/.local/python
.bachrc的位置: /home/joey/.bashrc
2.pychram 中没有opencv的智能提示:(linux)
1 | 在 opencv 的 __init__.py 中修改为:import sys |
3.pychram 中没有opencv的智能提示:
win10参考博客:blog
- 配置opencv pip -install opencv-python
- 将./cv2/下的cv2.cp37-win_amd64.pyd 文件拷贝到site-pachages目录下
- import cv2 ok
4.python 继承
在子类中必须要执行父类的构造函数
1 | class B(A): |
5.重写Model 类
在Model类中可以实现网络结构以及前向、候选传播函数
1 | class Model(torch.nn.Module): |
计算网络中的参数
(n-2p-f)/s + 1 = 图像边长.
训练模型MNIST模型:
1 | import torch |
损失函数
cost = torch.nn.CrossEntropyLoss()softmax损失- 定义cost对象,之后计算只用传入数据即可
- 需要注意的是
loss = cost(y_pred,var_y)输入时有顺序的先写预测,再写label
cost = torch.nn.MSELoss()欧式损失
优化算法
optimizer = torch.optim.Adam(model.parameters())- 定义opt对象,可采用自定义优化算法,需要将model的参数全部传入,以算法进行计算。
- 需要注意的是:
optimizer.zero_grad(),每次更新w前,需要将上一次迭代的梯度清理。
关于data_loader_train、data的说明:
data_loader_train是整个数据集data_loader_train一次生成batch_size个数据
shape= (64,1,28,28)
所有第二个for是整个batch_size的矩阵计算
Model的forward()
自定义Model继承了Module后需要重写父类的 forward()函数
即计算整个计算图。y_pred = model(var_x)需要注意的是:
model(var_x)的输入参数必须是Variable类型,需要转换。
torch.max()
排列得到最优解,
torch.max(data,dim)
与python中argmax(data,dim)有着差不多的功能,其返回值有2个,一个是获得最大值的值,以及其索引。
1 | a = torch.tensor([[1,3,2],[4,1,3]]) |
类似与python中这种带维度的比较技巧
torch.max(a,dim)
dim 维度 依次递增,其他维度不变,遍历得到各个数据之间相互比较得到样例
1
2
3
4
5torch.max(a,0)
a = [
[1,3,2],
[3,2,1]
]保持第1维度不变,0维度遍历。
a[0][0] a[1][0] a[2][0] 比较一次 输出一次结果
a[0][1] a[1][1] a[2][1] 比较一次 输出一次结果
T20190705:
GPU训练MNIST
数据的载入:
1. 使用torch.utils.data.DataLoader()
1 | data_loader_train = torch.utils.data.DataLoader( |
batch_size指定了数据中每次读入的数据量。dataset指定了数据集data_train是torchvision.datasets类。datasets分多种,在MNIST中使用的是1
2
3
4
5
6datasets.MNIST(
root = "./data/",
transform = transform_,
train = True, #是训练集
download = False #使用本地的训练集
)
从Dataloader中读出数据:
1 | x,y = next(iter(dataloader["train"])) |
将dataloader强制转为迭代器,然后用next读出一个batch
注意读出的数据是tensor形式,有时需要转为numpy的格式,使用tensor.numpy()即可。而从numpy构造tensor可以 torch.from_numpy(array).float(),需要指定数据格式,torch中需要float的数据。
Transforms
包名torchvision.transforms1
2
3
4
5
6transforms.Compose(
[
transform.ToTensor(),
transform.Normalize(mean = .5,std = .5)
]
)
Pytorch读入数据时需要的步骤:
数据集的准备:
数据库的获得:raw data:可以是文件夹中的图片:直接用dataset.
torchvision.datasets:中
torchvision.datasets.DatasetFolder(暂无信息。)torchvision.datasets.ImageFolder
1 | dset.ImageFolder(root="root folder path", [transform, target_transform]) |
torchvision.datasets 是继承自torch.utils.data.Dataset
torch.utils.data.TensorDataset(data_tensor, target_tensor)
这让函数可以将tensor数据转为数据集
样例:
新建两个np.array类型的数据转为tensor再转为dataset
将np->转为Tensor: torch.from_numpy(train_x).float()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44#tain data
train_x = np.linspace(-6, 8, self.N_SAMPEL)[:,np.newaxis]
# print(type(self.x))
self.bias = 5
self.noisy = np.random.normal(0,2,train_x.shape)
train_y = np.power(train_x,2) + self.bias + self.noisy
# print(self.x.shape)
# self.plot_data(train_x,train_y)
# test data
test_x = np.linspace(-7, 10, 200)[:, np.newaxis]
noise = np.random.normal(0, 2, test_x.shape)
test_y = np.square(test_x) - 5 + noise
# self.plot_data(test_x,test_y)
# plt.plot(train_x,train_y,'o',color= "blue")
# plt.plot(test_x,test_y,'+',color = "red")
# plt.show()
#装载到dataloader里面:
train_x = torch.from_numpy(train_x).float()
train_y = torch.from_numpy(train_y).float()
test_x = torch.from_numpy(test_x).float()
test_y = torch.from_numpy(test_y).float()
data = {
"train":
{
"x":train_x,
"y":train_y
},
"test":
{
"x":test_x,
"y":test_y
}
}
da_i = torchvision.datasets.ImageFolder()
da = torchvision.datasets.DatasetFolder()
dataset = {x: Data.dataset.TensorDataset(data[x]["x"],data[x]["y"]) for x in ["train","test"] }
dataloader = {x : Data.DataLoader(dataset = dataset[x], batch_size = self.BATCH_SIZE, shuffle= True) for x in ["train","test"] }
使用GPU处理数据:
model = Model()
model.cuda() 开启GPU训练模式
如果要使用GPU训练,则所所有数据必须转换成cuda的形式
需要转换的地方:
损失函数的转换:
- cost = torch.nn.CrossEntorpyLoss()
cost.cuda()
- cost = torch.nn.CrossEntorpyLoss()
变量的转换:
1 | for data_t in data_loader_train: |
- cpu->gpu:
variable(x).cuda()
gpu->cpu:
cuda_var(x).cpu()
T20190707
Pytorch 数据结构:
Model
Model 类来自package: torch.nn.Module
其中会有定义的网络Sequential参数,比如定义了 conv1 在其下有_modules参数:可以在着拉看到每一层的data。在该层变量中,可以看到其中包含的参数,其中比较重要的是:
weightbiasdense
2. datasets:
- 在
datasets类中主要负责数据的读入,所以数据的增强以及数据的修建放在了这里。transform参数很好的体现了这一点。 datasets来自package:torchvision.datasets- 目前学习到的数据集类有:
ImageFolder每一个文件夹为一个类,加载后,同一个文件夹下的label是一致的。
1 | image_dataset = { x: torchvision.datasets.ImageFolder( |
- 在ImageFolder 中,datasets含有以下数据结构:
class_to_idxdict{标签名称与对应索引的字典}classeslist[标签名称]imgslist[tuple(‘Image完整路径’,’对应label索引’)]targetslist[lable]transform
1 | print(len(image_datasets["train"])) # 20000 注意可能image_datasets是字典类型!分了train,test,valid |
MNIST直接对MNIST数据集进行加载
3. DataLoader:
DataLoader中设置batch_sizeDataLoader在package:torch.utils.data.DataLoader中DataLoader这个类是用来装载datasets中的数据的,因为数据集可能很大,DataLoader划分batch_size装载,并且可以shuffle读入。- 使用生成器或者迭代器就可以获得每一个batch的数据,数量是一个batch_size的数据,顺序是shuffle后的数据。
len(dataloader)#好像和len(image_dataset)不一样
4. Model类:
1. 试例代码1
1 | class Model(torch.nn.Module): |
2. 试例代码2
1 | import torchvision.models as models |
models.vgg16(pretrained =True) pretrained =True表示不下载模型
model:包含了所有参数
model_modules: OrderedDict类型,字典类的派生,键值为模型中定义的网络块(Sequential定义的名称就为定义的名字,其值为Sequential类型包含了定义的所有层)
feature_layers: Sequential类型包含了各种层,也可以直接model.feature访问,因为其feature相当于是model的一个公变量
layer: 层的定义类型,conv层是conv层类型,pool层是pool层类型,包含各自的参数,也可以通过 feature_layers 下标访问。其中比较重要的有:
- weight : parameter类型
- bias : parameter类型
样例:
1 | #全冻 |
Parameters():
凡是关于参数的,都使用Parameters()来进行操作
model.parameters(): 返回的是所有参数的生成器,每个item是parameter类型,包含Tensor,requires_grad等类型。无法下标访问 注意的是requires_grad 是有s的
parame 即生成器的返回变量,拥有data参数,可以访问到该的数据,有grad,shape,等。
新建的Sequential是默认可以更新的。
model.Classifier 可以直接操作整个Squential
T20190711:
loadModel
model.load_state_dict(torch.load("checkPoints/LLModel_0708_21:54:25.pth"))
model的加载是使用.load_state_dict()
torch.load("checkPoints/LLModel_0708_21:54:25.pth") 这个得到的是一个OrderDict,包含了每一层的参数(有参数的参数层,像Pool层是没有的)
1 | model_path = "/home/joey/Documents/models" |
显存的节约
在测试或验证集的预测中,不要带有梯度可以省去一大步分的cuda,GPU显存。可以一定程度上缓解CUDA.memery的问题。1
2
3
4
5
6if phrase == "valid":
with torch.no_grad():
x,y = Variable(x).cuda(),Variable(y).cuda()
y_pred = model(x)
_,y_pred_class = torch.max(y_pred,1)
loss = loss_f(y_pred,y)
T20190726:
optim
优化函数可以只传入模型的部分参数:1
optimizer = torch.optim.Adam(model.Classifier.parameters(),lr = lr)
仅仅传入最后全连接层的参数,存疑这样是否就可以不用设置冻结之前层?
《pytorch-cv》是既设置了冻结,又只传入了部分参数
T20190729:
st-gcn Code Analyze:
1 | mod_str, _sep, class_str = import_str.rpartition('.') |
rpartition() 方法类似于 partition() 方法,只是该方法是从目标字符串的末尾也就是右边开始搜索分割符。
如果字符串包含指定的分隔符,则返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串。
实例:
1 |
|
import:
__import__() 函数用于动态加载类和函数
1 | __import__(mod_str) |
源码中首先使用importclass的方法,传入文件名以及类名。
然后使用`_import`来加载类。只是申明并未实例化。
得到的processors是一个字典,包含了两个类1
2processors['recognition'] = import_class('processor.recognition.REC_Processor')
processors['demo'] = import_class('processor.demo.Demo')
import()的一个小实例:
文件T20190801中:1
2
3
4
5
6
7
8
9
10
11
def import_model(self,str):
mod_str, _sep, class_str = str.rpartition('.')
__import__(mod_str)
return getattr(sys.modules[mod_str], class_str)
def start(self):
train_x,train_y,test_x,test_y = self.makedata()
Model = (self.import_model("T20190801_Model.Model"))
model = Model()
print(model)
__import__(mod_str)中只有传入文件名称就可以导入该文件了.
getattr(sys.modules[mod_str], class_str) 可以得到class_str这个类,相当于类的申明。
可以使用这个申明来实例化类对象
文件T20190801_Model中:1
2
3
4
5
6
7
8
9
10
11
12
13
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.classification = nn.Sequential(
nn.Conv2d(1, 20, 5),
nn.ReLU(),
nn.Conv2d(20, 64, 5),
nn.ReLU()
)
def forward(self):
pass
parse 以及 subparsers:
每一个subparser可以继承父类的parse1
2
3
4# add sub-parser
subparsers = parser.add_subparsers(dest='processor')
for k, p in processors.items():
subparsers.add_parser(k, parents=[p.get_parser()])
k是键,{"recognition" "demo"},即parser的名称,注意后面使用parse_args()时所输入的子parser器名称必须要和其一样。不然会报错。详细见下面例子
实例:1
2
3python3 main.py recognition -h #正确调用,因为parser有名为recognition的parse
python3 main.py sdeqds -h #错误,找不到名为sdeqds子parse。
p是值,包含了两个类。
p.get_parser()可以进入到该类的get_parser方法中
在对应的类中,get_parser都会执行。
subparsers = parser.add_subparsers(dest='processor')得到的subparsers可以有多个parser,相当于parser的子parsers的句柄。向其中加入parser使用add_parser即可
parser.add_subparsers(dest=’processor’)返回的是子parser的句柄!!
使用add_parser()向subparsers中加入parser
add_parser(“名字”,parent = “父parser”)。
recognition类的get_parser1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21def get_parser(add_help=False):
# parameter priority: command line > config > default
parent_parser = Processor.get_parser(add_help=False)
parser = argparse.ArgumentParser(
add_help=add_help,
parents=[parent_parser],
description='Spatial Temporal Graph Convolution Network')
# region arguments yapf: disable
# evaluation
parser.add_argument('--show_topk', type=int, default=[1, 5], nargs='+', help='which Top K accuracy will be shown')
# optim
parser.add_argument('--base_lr', type=float, default=0.01, help='initial learning rate')
parser.add_argument('--step', type=int, default=[], nargs='+', help='the epoch where optimizer reduce the learning rate')
parser.add_argument('--optimizer', default='SGD', help='type of optimizer')
parser.add_argument('--nesterov', type=str2bool, default=True, help='use nesterov or not')
parser.add_argument('--weight_decay', type=float, default=0.0001, help='weight decay for optimizer')
# endregion yapf: enable
return parser
调用处:subparsers.add_parser(k, parents=[p.get_parser()])
返回了一个parser
这个parser继承了Processor的parser,并且添加了自己的参数。
各个类的父子关系:1
2
3|IO----|----demo
|
|----processor----|----REC_Processor
subparser的作用可以复用相同的参数接口
所有parser写完后调用根parse进行解析:
parser = argparse.ArgumentParser(description='Processor collection')subparsers = parser.add_subparsers(dest='processor'),添加子解析器
…arg = parser.parse_args(),开启解析,定义了所有参数之后,你就可以给parse_args()传递一组参数字符串来解析命令行。默认情况下,参数是从 sys.argv[1:] 中获取,但你也可以传递自己的参数列表。选项是使用GNU/POSIX语法来处理的,所以在序列中选项和参数值可以混合。
parse_args() 的返回值是一个命名空间,包含传递给命令的参数。该对象将参数保存其属性,因此如果你的参数 dest 是 myoption,那么你就可以args.myoption来访问该值。
- 可以自己向parse_args中传递参数:
1
parser.parse_args(['-a', '-bval', '-c', '3'])
如果不parse_args()不加参数则是默认从sys.argv[1:]来传入
argparse.add_argument() dest参数的意义:
subparsers = parser.add_subparsers(dest='processor')
dest指定的值用作key值,从解析后的对象中取出用户输入的第一个参数
所以上述的parser拥有一个arg.processor的属性。而这个属性对应了cmd中第一个输入值。
得到类对象:
1 | Processor = processors[arg.processor] |
processors中存储了两个类,只不过这两个类还并未实例化。p = Processor(sys.argv[2:])实例化了此类。
recognition构造函数:
先执行父类的构造:1
2
3
4
5
6
7
8
9
10
11
12"""
Base Processor
"""
def __init__(self, argv=None):
self.load_arg(argv)
self.init_environment()
self.load_model()
self.load_weights()
self.gpu()
self.load_data()
self.load_optimizer()
调用处:p = Processor(sys.argv[2:])传入了argv
这里的Processor是recognition类中的REC——Processor
在该类中没有构造函数,会调用父类的构造函数。
sys.argv
列表,包含了执行文件的路径+所有输入的参数。以空格分开。['/media/joey/document/[3]_Master/DL/8_ActionRecognize/GCN_ACTION_R/st-gcn_code/st-gcn-master/main.py', 'recognition', '-c', 'config/st_gcn/kinetics-skeleton/test.yaml']
在实例化中只传入了下标2-end的参数:
'-c''config/st_gcn/kinetics-skeleton/test.yaml'
执行load_arg(argv)
1 | def load_arg(self, argv=None): |
需要指出的是在这里如果直接用argv来获取参数,是获取不了默认填充的参数的,除非用户将所有参数填写完,那些可选的,有默认值的参数,通过sys.argv,是获取不了的,其只能获取实实在在输入的参数。
所有如果要获取arg所有的参数,必须要通过已经填充好的parser来获得。
执行init_environment():
1 | def init_environment(self): |
配置环境,以及实例化IO类,IO类主要负责了模型的读取存储等操作。
执行self.load_model():
先执行父类的load_model():1
2
3def load_model(self):
self.model = self.io.load_model(self.arg.model,
**(self.arg.model_args))
其中io是在init_environment中定义的。
io.load_model():1
2
3
4
5def load_model(self, model, **model_args):
Model = import_class(model)
model = Model(**model_args)
self.model_text += '\n\n' + str(model)
return model
可以看出io中的load_model()才是真正的加载模型。
在recognition中
model='net.st_gcn.Model'{str}model_args= 网络参数 {dict}
导入类后在实例化。
net.st_gcn.Model
真正的网络模型:
1 | class Model(nn.Module): |
Graph类:

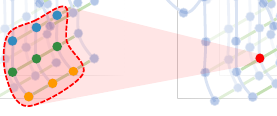
有了这个原理示意图就可以很好的理解这篇paper在graph的操作了。
输入多帧数据很好理解。中间得到skeleon输入到网络中
ST-GCNS的处理过程在图中表达的很清楚。留意红点的位置

|
|
| Graph的构建 1 | Graph的构建 2 |
论文中类比了2D CNN,个人觉得很形象,在这里解释下: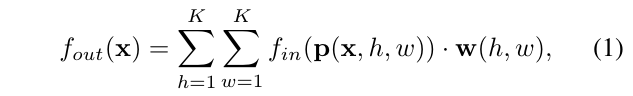
其中P是抽样函数,将原图中的像素抽取出来进行操作,w是对应的权重,即所谓的核。
两个加权则是卷积了,将抽出来的每个像素值与对应的w做积然后相加,最后就可以得到该位置的卷积后的值。
当然这和我们之前所见的卷积公式有所不同,作者是为了抽象得到更高层相同的架构而这样写的,方便读者之后理解GCN
上面的公式表明,只要知道了抽样函数、寻找对应的权重的方法,我们就可以实现广义的卷积了。图卷积正是这样产生的:
定义抽样函数:
在CNN中,抽样函数可以看作是一个矩阵抽样,依次按照卷积核的大小,以任意顺序跑完核对应的Pixel的积运算。
不难想到在图这种数据结构下,利用最短路径来抽样是首选方法。
定义B(vti)邻接点的集合: $(v_tj) 当点与中心点的最短距离小于D时可以视作抽样点。在论文中作者D取的1
中心点可以类比与卷积的中心点,其他邻接点可以看作卷积核作用的其他点,以3×3的卷积核为例,中间点就是vti,其他8个点就是vtj。(数量可能不同因为小于1的图中的点集可能少于8个)
但是可以发现的是,随着D的确定,Graph卷积核只有一维,但是CNN中卷积核是2维的矩阵。
所以作者将graph的第二维放在了时间上。对于相邻帧的点作者也给予抽样,这样既满足了action recognition的视频流训练,也满足了二维核的缺失。
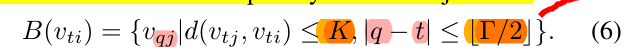
对于相邻帧也给予抽样,这个公式还算好理解,q的范围是t+-r/2,所以可以看出在tao的区间中进行抽样,抽取q帧中,每一个在t帧的邻接点的投影。
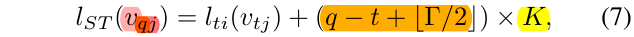
其子集名称则是 原来子集名称的 0K - rK 偏移得到的值。关于子集名称再之后会解释。
定义权重函数:
Instead of giving every neighbor node a unique labeling, we simplify the process by partitioning the neighbor set B(vti ) of a joint node vti into a fixed number of K subsets, where each subset has a numeric label.
文章中说到不给每一个节点单独的labeling,而是将邻接点s归为不同的sub,然后每一个sub含有其自己的数字label。一共有K类。,lti返回的是t帧i号节点的subset的label。
所以综上,GCN可以表达为: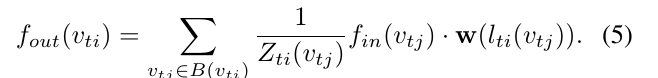
w(lit(vtj))表明了不是每一个点都会有weight,而是一个subset一个weight。与CNN有所不同。
subset的定义:
文章中提出了3中分点的方法:
Uni-labeling,全部B(vti)分为一个subset,但是这样会失去局部的特点属性。只需要将K = 1,且lti(vtj) = 0即可,这就表明了只有1个类,且所有vti的subset序号为0。Distance partitioning安装距离来分子集,分为root点和其他点。只需要将K = 2,且lti(vtj) = d(vtj,vti)即可,因为D=1,所以d()只能为0-1之间的两个值。Spatial configuration partitioning根据空间的分区。
作者基于body motion 可以被大致的分为近重心运动以及偏重心运动。所以将远离中心的节点分为一类,将近心的分为一类,根分为一类,一共三类。1
2
3l_ti(v_tj) = 0 if rj = ri
= 1 if rj < ri
= 2 if rj > ri
r_i is the average distance from gravity center to joint i over all frames in the training set.
注意是该点所有帧的距离重心平均距离。
np.linalg.matrix_power(matrix, expo)
方矩阵乘法.
- expo > 0 进行matrix的连成。
- exp0 = 0 对角矩阵
- expo =-1 逆矩阵,
- expo < 0 matrix(-expo),即 matrix × matrix × np.linalg.matrix_power(matrix, 2) = eyes()
range:
range(2) -> [0,1]产生两个数,即range(n) 产生n个数,从0开始
range(2,-1,-1): start,end,step -> [start,end)
pytorch 中 register_buffer
注册变量,A是tensor变量。在之后的调用只用self.A_即可调用1
self.register_buffer('A_',A)
Pytorch参数其实包括2种。一种是模型中各种 module含的参数,即nn.Parameter,我们当然可以在网络中定义其他的nn.Parameter参数;另外一种是buffer。前者nn.Parameter中的参数每次optim.step会得到更新,而不会更新后者buffer。buffer的更新在forward中,optim.step只能更新nn.Parameter类型的参数。
python 中 三元表达式:
如果 i = 0 a为1,否则a = 101
2
3i = 1
a = 1 if i == 0 else 10
print(a)
Pytorch中的模型层的搭建:
- 使用
nn.Sequential()来搭建
一个时序容器。Modules 会以他们传入的顺序被添加到容器中。当然,也可以传入一个OrderedDict。nn.Sequential()的输入参数可以是多个torch.nn.对象。
为了更容易的理解如何使用Sequential, 下面给出了一个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38def __init__(self):
super(Models, self).__init__()
self.Conv = torch.nn.Sequential(
torch.nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(32, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2)
)
self.Classes = torch.nn.Sequential(
torch.nn.Linear(9 * 9 * 64, 1024),
torch.nn.ReLU(), torch.nn.Dropout(p=0.5),
torch.nn.Linear(1024, 1024),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(1024, 45)
)
# Example of using Sequential
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Example of using Sequential with OrderedDict
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
OrderedDict可以存储层的名字,输出是这样的1
2
3
4
5
6(ta): Sequential(
(conv1): Conv2d(1, 20, kernel_size=(5, 5), stride=(1, 1))
(relu1): ReLU()
(conv2): Conv2d(20, 64, kernel_size=(5, 5), stride=(1, 1))
(relu2): ReLU()
)
而直接使用Sequential输出是这样的:1
2
3
4
5
6
7
8
9(Classes): Sequential(
(0): Linear(in_features=5184, out_features=1024, bias=True)
(1): ReLU()
(2): Dropout(p=0.5)
(3): Linear(in_features=1024, out_features=1024, bias=True)
(4): ReLU()
(5): Dropout(p=0.5)
(6): Linear(in_features=1024, out_features=45, bias=True)
)
默认从0开始的标号作为其层的名字
使用
nn.ModuleList()来搭建nn.ModuleList()的输入参数是一个元组,包含了所有的Module
而st-gcn中正是使用ModuleList来wrapst_gcn这个自定义层的。1
2
3
4
5
6
7
8
9
10
11
12self.st_gcn_networks = nn.ModuleList((
st_gcn(in_channels, 64, kernel_size, 1, residual=False, **kwargs0),
st_gcn(64, 64, kernel_size, 1, **kwargs),
st_gcn(64, 64, kernel_size, 1, **kwargs),
st_gcn(64, 64, kernel_size, 1, **kwargs),
st_gcn(64, 128, kernel_size, 2, **kwargs),
st_gcn(128, 128, kernel_size, 1, **kwargs),
st_gcn(128, 128, kernel_size, 1, **kwargs),
st_gcn(128, 256, kernel_size, 2, **kwargs),
st_gcn(256, 256, kernel_size, 1, **kwargs),
st_gcn(256, 256, kernel_size, 1, **kwargs),
))使用类属性注册搭建:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18for id in range(self.hiden_Num):
inSize = 1 if id ==0 else 10
fc = nn.Linear(inSize,10)
self.feature.add_module('fc_%i' % id, fc)
# setattr(self.feature, 'fc_%i' % id, fc) # 注意! pytorch 一定要你将层信息变成 class 的属性! 我在这里花了2天时间发现了这个 bug
self._set_init(fc) # 参数初始化
self.fcs.append(fc)
if use_Bn:
bn = nn.BatchNorm1d(10,momentum=0.5)
setattr(self.feature,'bn_%i'%id,bn)
self.bns.append(bn)
re = nn.ReLU()
self.feature.add_module('relu_%i' % id, re)
self.predict = nn.Linear(10, 1) # output layer
self._set_init(self.predict) # 参数初始化
setattr(self.feature, ‘fc_%i’ % id, fc) 也可以在序列中添加层,以达到类似于Sequential(OrderDict[])的效果。1
2
3
4
5
6self.feature = nn.Sequential() # 新建一个序列对象。
inSize = 1 if id ==0 else 10
fc = nn.Linear(inSize,10)
setattr(self.feature, 'fc_%i' % id, fc) #向序列中添加层
re = nn.ReLU()
self.feature.addmodule(‘fc%i’ % id, fc)
也可以调用Sequential的add_module()函数添加层
Pytorch中的BatchNom1d():
这里将把一次训练过程进行剖析,获得其中的中间数据,然后展现BatchNom的效果,BatchNom的作用主要是防止数据在进入激活函数activation时其分部大多在未激活区,如ReLU的负数区域,sigmoid的趋近于1的区域,这些区域在计算梯度时都为0,无法达到后向传播的功能。并且如果核的权重初始化不正确(大概率),以ReLU为例:输入数据在第一层与核函数进行计算后,数据很可能有大部分处于负数区域,一旦数据处于负数区域,其激活值是0,那么之后的该点的激活值都是0,WX+B,B未正确初始化(大多为负数,这样WX=0+B必小于0),之后的所有ReLU层都会小于0,那样网络就死掉了,其他的激活函数类比ReLU。
所以大多时候如果我们的代码是正确的,但是老是train不起来,浅层的梯度很小或等于0,那么这时很有可能是我们的初始化不对,且没有进行BN。
这个情况很常见,在我之前train那篇东南大学的手势估计文章时(毕设)就没有考虑到这个问题,网络中的梯度流老是在0附近,并且我的代码应该是正确的,caffe训练本来就不需要什么代码。但是我没有使用pycaffe接口,没有对每一层进行权重的初始化,那么框架就会自动进行初始化,很可能我们的核权值就会让数据处于ReLU的负数区域,那么之后再怎么train都是徒劳的。
添加BN的位置也需要注意,input_data -> BN_for_data -> 核 -> BN -> action -> 核 -> BN -> action …
其位置是在进入激活函数之前,将上一个核函数计算得到的数据进行BN,然后输入进激活函数中。如果在激活函数之后,那么核产生的非激活数据仍然会进入核函数,其输出就是0,或者梯度回播就是0,那么之后再输入BN也无济于事。所以BN的位置是在核函数之后,激活函数之前
BN的对比图如下:
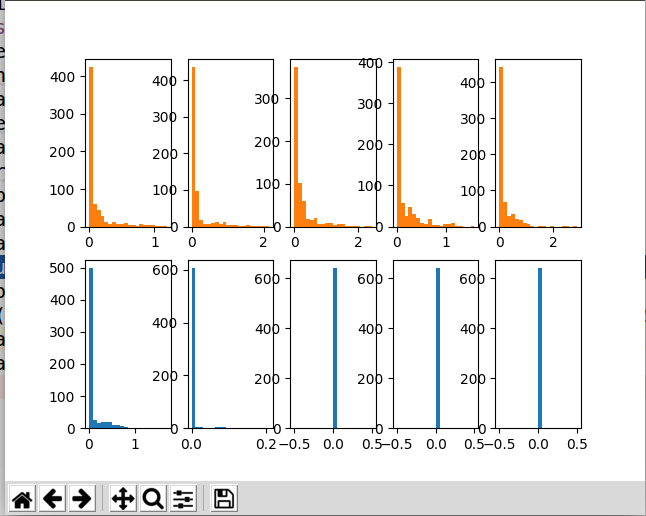
橘黄色的是有BN处理的,蓝色的是没有BN处理的。
1 | def forward(self,x): |
代码中的befAction 与 aftAction 只是记录了输入激活之前之后的x的数值,不是BN的位置,不要和之前的搞混了。
pytorch的forward函数即是前向计算的函数,可以将每一层的计算和联系体现出来。具体针对每一层的操作我目前想到的方法只是从layer.str来区分,是否存在其他方法可以直接提出层的属性?比如提出conv、pool、BN等类别?
可以在forward函数中做很多工作,在一个模型中的forward采取另一个模型进行forward也未尝不可。但是其backward会出现问题…这时题外话了,没有人会这样骚操作。
从PyTorch中取出数据进行numpy操作:
如果对象是Variable类型,取出其数据需要注意以下几点:
- 如果是有grad_requires = True的,那么需要with torch.no_grad()申明
- 如果不使用with torch.no_grad,也可以使用x.cpu().detach().numpy()来获得
- 如果在gpu上的数据,需要使用data_x.cpu放在cpu上
- 数据得到后Tensor 2 numpy只需要执行 tesnor.numpy即可
1 | x,y = next(iter(dataloader["test"])) |
一个拟合2次曲线的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37def train(self,dataloader):
self.model.cuda()
opt = torch.optim.SGD(self.model.parameters(),lr=0.001)
loss_f = torch.nn.MSELoss()
for epoch in range(self.EPOCH):
for phase in ["train", "test"]:
loss_epoch = 0.0
acc_epoch = 0.0
for batch_n, data in enumerate(dataloader[phase],1):
x,y = data
x,y = Variable(x).cuda(),Variable(y).cuda()
pre = self.model.forward(x)
opt.zero_grad()
loss = loss_f(pre,y)
if phase == "train":
loss.backward()
opt.step()
loss_epoch += loss
if phase == "train" and batch_n % 10 ==0:
print("+" * 30)
loss_batch_ave = loss_epoch.__float__()/(batch_n.__float__())
print("loss = %.2f"%loss_batch_ave)
if (phase == "train"):
print("+"*30)
print("train")
print("epoch:{}/{} loss = {}".format(epoch + 1,self.EPOCH,loss_epoch.__float__()/batch_n.__float__()))
if(phase == "test"):
print("+"*30)
print("Test:")
print("epoch:{}/{} loss = {}".format(epoch + 1, self.EPOCH, loss_epoch.__float__() / batch_n.__float__()))
x,y = next(iter(dataloader["test"]))
with torch.no_grad():
x, y = Variable(x).cuda(), Variable(y).cuda()
pre = self.model.forward(x)
plt.plot(x.cpu().numpy(),pre.cpu().detach().numpy(),'x')
plt.plot(x.cpu().detach().numpy(),y.cpu().detach().numpy(),'o')
plt.show()
各个框架之间conv2d的区别:
这里也可视化了dilated conv的作用
疑问的产生处是这里,在之前没有遇见过conv2d()中的kernel_size、stride是元组的情况
1 | torch.nn.Conv2d( |
参考pytorch中文文档的解释:1
class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
bigotimes: 表示二维的相关系数计算stride: 控制相关系数的计算步长dilation: 用于控制内核点之间的距离,详细描述在这里groups: 控制输入和输出之间的连接:group = 1,输出是所有的输入的卷积;group=2,此时相当于有并排的两个卷积层,每个卷积层计算输入通道的一半,并且产生的输出是输出通道的一半,随后将这两个输出连接起来。- 参数
kernel_size,stride,padding,dilation也可以是一个int的数据,此时卷积height和width值相同;也可以是一个tuple数组,tuple的第一维度表示height的数值,tuple的第二维度表示width的数值
1 | #with square kernels and equal_stride |
如果Conv传入的是元组,即两个方向上的参数,而不是之前默认的正方形的核、或者移动了。
Pytorch 中的 view()
把原先tensor中的数据按照行优先的顺序排成一个一维的数据(这里应该是因为要求地址是连续存储的),然后按照参数组合成其他维度的tensor。比如说是不管你原先的数据是[[[1,2,3],[4,5,6]]]还是[1,2,3,4,5,6],因为它们排成一维向量都是6个元素,所以只要view后面的参数一致,得到的结果都是一样的。
总之一句话: 行优先的视图排列1
2
3
4
5
6t = torch.randn(2,1,3,4)
print(t)
y = t.view(4,6)
y[0] = 1
print(y)
print(t)
视图的操作可以对原来的数据进行抽象的修改,从不同视图来修改数据。view() 得到的数据不会分配内存。
而tensor的view()操作依赖于内存是整块的,如果当前的tensor并不是占用一整块内存,而是由不同的数据块组成,那么view()将报错。
而为了使得view能操作这些非同块内存的数据,Pytorch提供了一个contiguous函数来将分散的数据块整合成一块。
给一个例子方便理解:1
2
3
4
5
6
7
8
9import torch
x = torch.ones(5, 10)
x.is_contiguous() # True
x.transpose(0, 1).is_contiguous() # False
x.permute(1,0).is_contiguous() # False
x.permute(1,0).view(10,5) # 报错!
x.transpose(0, 1).contiguous().is_contiguous() # True
zip的用法:
将两个list横向组合,每一个小组和为一个元组,放进list中。
也可以解压,但是解压是在解压target前面加一个*号1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
a = [1,2,3]
b = [4,5,6]
c = [4,5,6,7,8]
zipped = zip(a,b) # 打包为元组的列表
## [(1, 4), (2, 5), (3, 6)]
zip(a,c) # 元素个数与最短的列表一致
## [(1, 4), (2, 5), (3, 6)]
zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式
## [(1, 2, 3), (4, 5, 6)]
nums = ['flower','flow','flight']
print(list(zip(*nums)))
# [('f', 'f', 'f'), ('l', 'l', 'l'), ('o', 'o', 'i'), ('w', 'w', 'g')]
numpy中concatenate函数:
将两个数组进行连接,前提是两个array,在拼接方向上满足形状一致即可。
切片操作:
通常一个切片操作要提供三个参数 [start_index: stop_index: step]
可以省略
start_index:[:5:2]意思为从数组头开始,到下标5结束每隔2个单位取一个,[5]不包括。可以省略
stop_index:[1::2]意思为从1开始到数组结尾,每隔两个取一个。可以省略
step:[1:6:] step = 1可以[::1] -> 从头到尾步长为1遍历
可以[::-1] -> 步长为-1时,当步长<0时,
start_index默认值为-1,stop_index为-len(a)可以[:-1:] -> 从头到最后一个元素依次遍历
1
2
3data_numpy[0, frame_index, :, m] = pose[0::2] #pose的偶数index的值
data_numpy[1, frame_index, :, m] = pose[1::2] #pose的奇数index的值
data_numpy[2, frame_index, :, m] = score
python OpenCV
video的读取操作:
cv2.VideoCapture()函数:
1 | cap = cv2.VideoCapture(0) |
cap.isOpened()函数:
返回true表示成功,false表示不成功
ret,frame = cap.read()函数:
cap.read()按帧读取视频,其中ret是布尔值,如果读取帧是正确的则返回True,如果文件读取到结尾,它的返回值就为False。frame就是每一帧的图像numpy_array类型
resize
1 | frame = cv2.resize(frame,(360,256)) |
circle
it 是元组类型(x,y)1
cv2.circle(frame,it,3,(0,0,255),3)
json文件加载:
1 | output_path = "/home/joey/datasets/hmdb/hmdb51_sta/pullup_json/50_pull_ups_made_in_germany_pullup_f_nm_np1_le_med_2.json" |
读出来后,对json的操作就和字典的操作一模一样。