An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
将transformer引入到了Image,代替了Conv,只是用transformer.
之前的难点:
- 相较于words token, 图像的每一个pixel没办法直接使用transformer,代价太大,每一个pixel都计算一次全局的self-attention的计算量很大。
- Transformer 没有平移不变性以及局部特性,在训练的时候如果没有大数据集,performance不如CNN。
Method
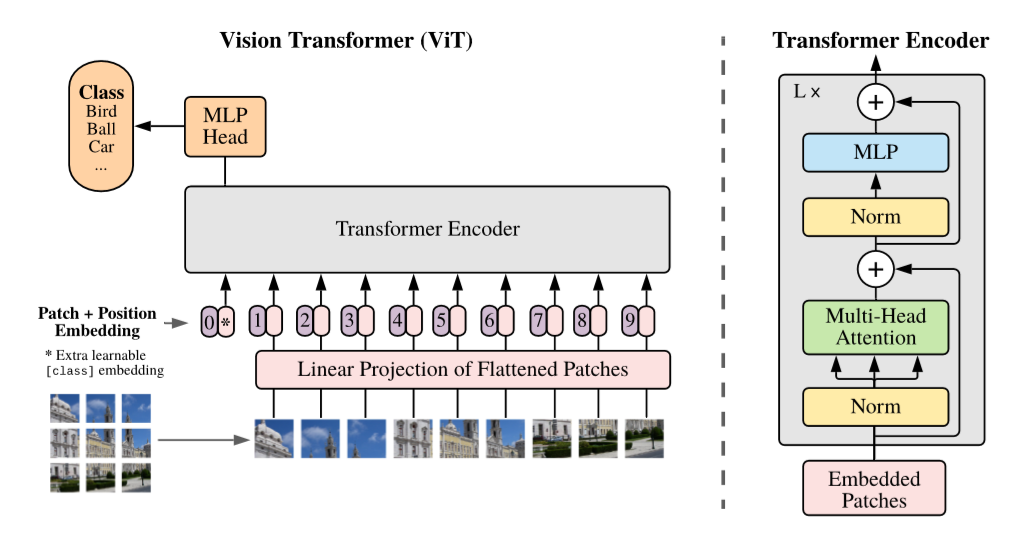
每一个patch当作是一个token,每一个token过linear projection,第一个token添加一个class token,Then 和位置编码相加,输入到transformer中。
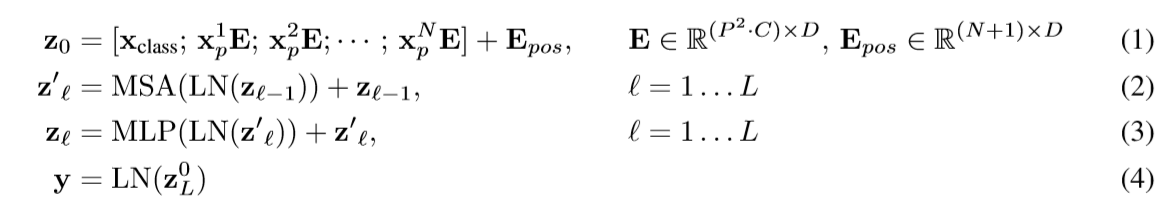
Transformer:
Transformer
1 | class Transformer(nn.Module): |
每一个token,预测qkv,通过qk计算attention,得到attentive的v。随后过一个FeedForward层。
Attention
1 | class Attention(nn.Module): |