SwinTransformer: Hierarchical Vision Transformer using Shifted Windows
- 提出了一个Hierarchical 架构的Transformer,让patch大小从小到大进行增加。为了减少计算cost,transformer的计算只在每一个window里面进行,并且为了消除只在window进行self-attention的操作,提出了使用shift-win的操作方式,让不同patch能够不局限于当前相邻的win分块。
- 提出了一种Hierarchical transformer, 每一层的patch大小不同,每一层会融合相邻patch得到一个更大的patch。
- 提出了一种win-shift方式,让网络的关注不limit到固定win中。
- 主要区别如文章teaser所示:
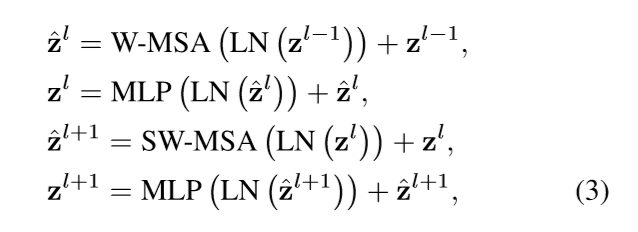

Method
输入图像首先进行patch partition, 每个patch大小是 $4 \times 4$ 大小,经过线性映射后输入到transformer中。
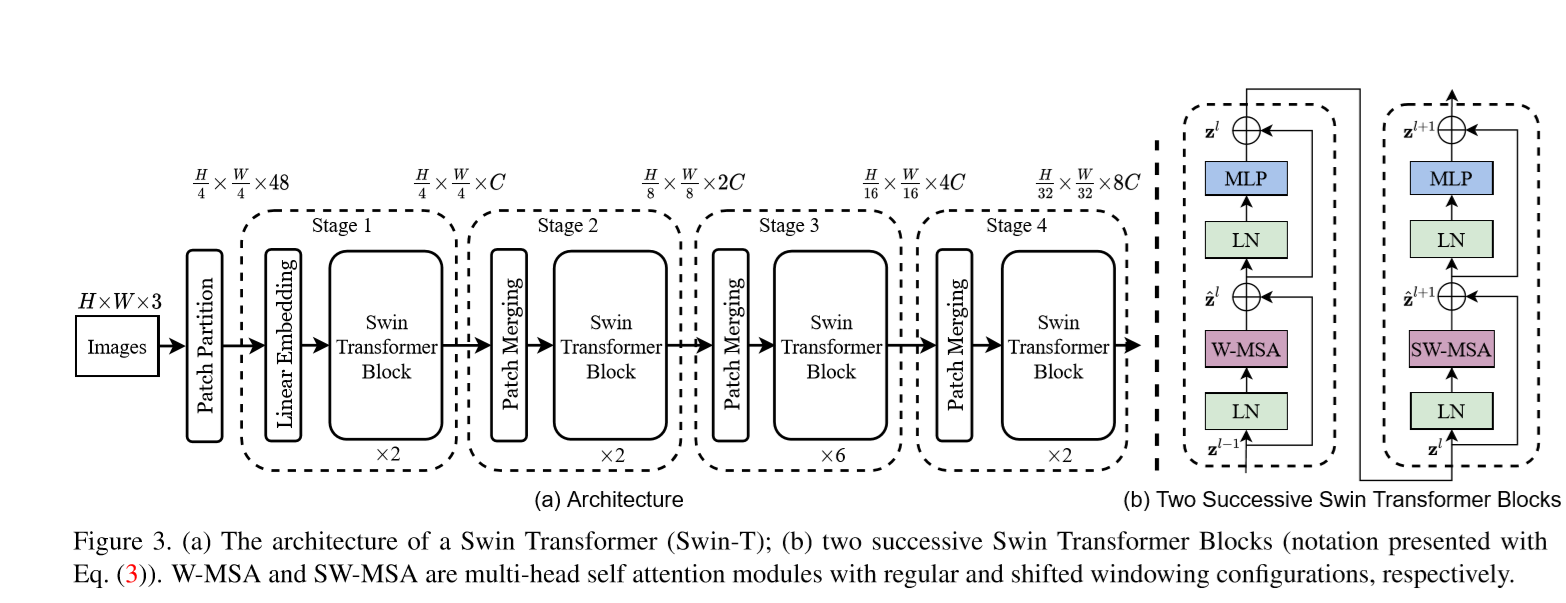
奇数层的Transformer 中的win不进行偏移(对应shift_size=0),每一个patch在win内部做self-attention。1
2
3
4
5
6
7
8
9
10self.blocks = nn.ModuleList([
SwinTransformerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer)
for i in range(depth)])
WindowAttention
1 |
|
Shift Win
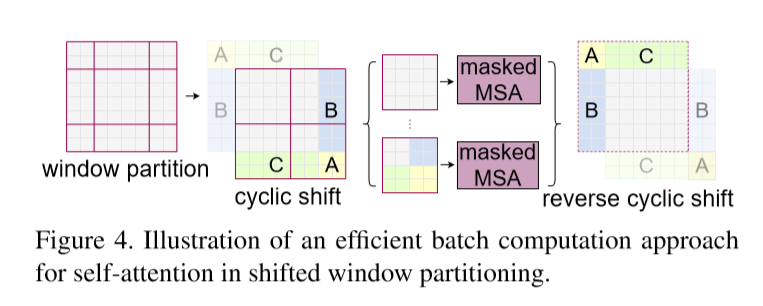
具体的将原来的图像feat.进行roll 操作,然后取win。这样每一个win所用于计算attention的patch就不局限与之前的win。增加了transformer的感受野。
After this shift,a batched window may be composed of several sub-windows that are not adjacent in the feature map, so a masking mechanism is employed to limit self-attention computation to within each sub-window.