Multi-Stage Progressive Image Restoration
Multi-stage networks are effective in high-level vision problems such as pose-estimation, action recognization. 但是目前的的multi-stage的NN要么采用encoder-decoder arch, this kind of arch 很容易去获得较广的纹理信息,但是lack of 保持空间细节。而单一大小的pipeline的话,容易保持空间细节但是语义信息比较难以获得。本文主要是想去Combine两者。
encoder-decoder的中skip是为了保持当前scale的空间细节信息,在reconstruct的时候添加原本由于down sample损失的信息,以便于网络去获得更多的空间细节信息。
作者还证明了直接将每一个阶段的output放入下一个stage的NN中是会降点的。
Method:
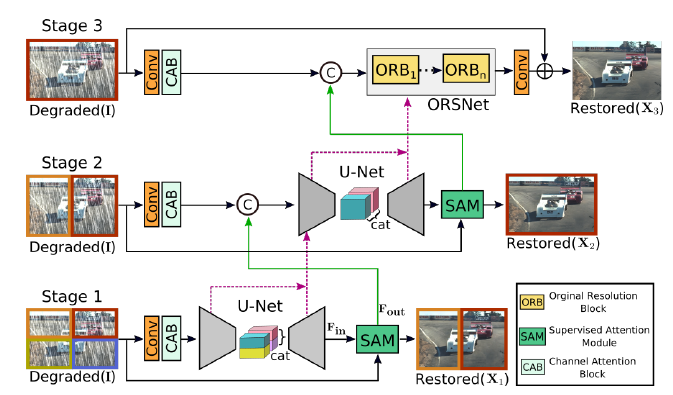
The earlier stages employ an encoder-decoder for learning multi-scale contextual information, while the last stage operates on the original image resolution to preserve fine spatial details
A supervised attention module (SAM) is plugged between every two stages to enable progressive learning. With the guidance of ground-truth image, this module exploits the previous stage prediction to compute attention maps that are in turn used to refine the previous stage features before being passed to the next stage
A mechanism of cross-stage feature fusion (CSFF) is added that helps propagating multi-scale contextualized features from the earlier to later stages.
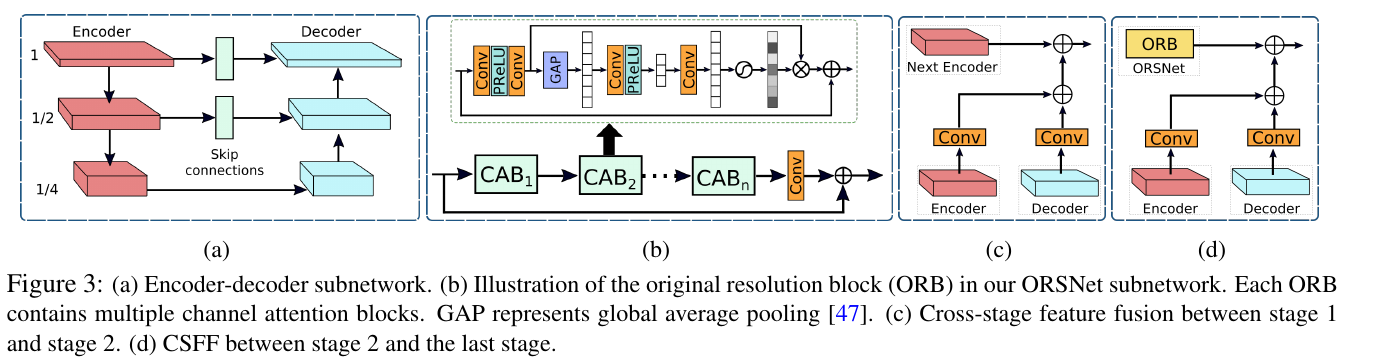
Encoder decoder Network:
- Channel attention blocks (CABs)
- The feature maps at U-Net skip connections are also processed with the CAB
- Bilinear upsampling followed by a convolution layer
Original Resolution Subnetwork:
In order to preserve fine details from the input image to the output image, generates spatially-enriched high-resolution features.
Supervised Attention Module
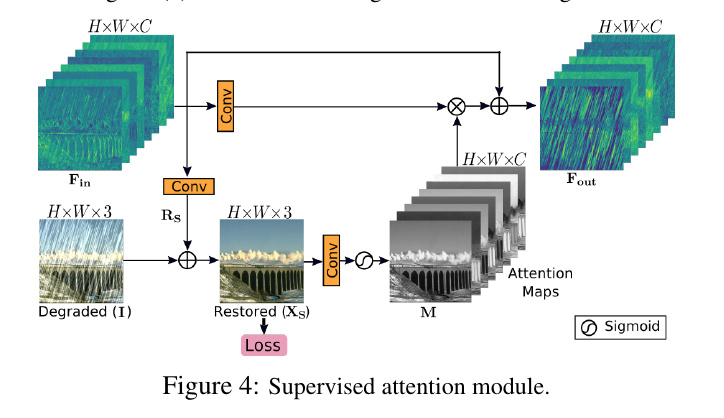
网络中不同stage中会将上一个stage的信息添加到该层stage 中,通过模块Cross-stage Feature Fusion module. 这样做有3个好处:
- 可以补充一些由于Up- down sample而丢失的信息。
- 上一阶段的特征可以丰富该阶段的特征。
- 网络变得更加的稳定。
消融实验
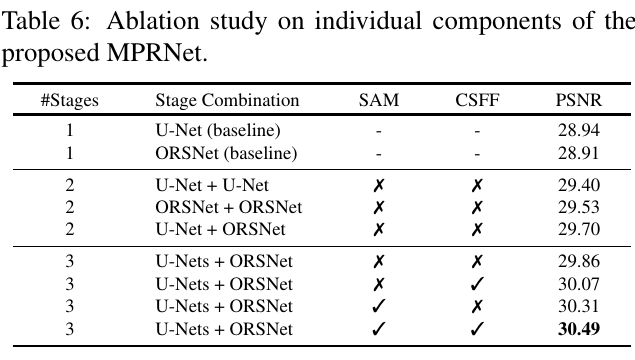
只用unet + unet; 只用SAM; …