总结下MM21投稿的工作(Multi-Decoder-based Patch-Adaptive Denoising Network)
- 一些小bug:framework中PFM名称没有修改
- sup中表有一个参考文献为 ?
分析两个问题:
- MDPA-Net 在SIDD上面能达到39.83,但是在DND只能上39.86, MIRNet,NBNet在SIDD分别是39.72和39.75,DND上面分别是39.88和39.89. 为什么差别这么大?
- 在提交DND的时候,有些图片存在明显的噪声,但是得分却较高。是GT本身就不能代表clean图像的分布吗?还是MDPANet比较依赖sensor?或者是数据集中的图像分布?我观测了SIDD中的图像,特别对比了两者。从个人角度觉得SIDD大多是室内,光线对比不强烈的图像,多在细节纹理的图片。DND的有很多建筑的,室外拍摄场景,明亮对比度更高,两者的数据分布差别很大。MDPA-Net在这种明暗交接的地方容易出问题,会不会是因为INS的问题?


- 上2点的处理方法有train一个自适应的去噪网络,将之前train好的数据进行fine tune 到下一个数据集中。参考paper有pseudo-ISP, cycle-ISP,感觉这个方向有不错的实用价值以及研究价值。
Multi-Decoder-based Patch-Adaptive Denoising Network
Motivation:
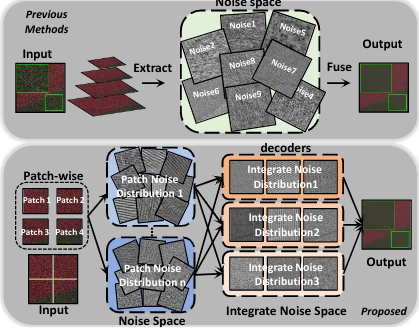
- 图像噪声分布的失真以及噪声消除不干净的问题:
在使用了down-sample操作得到各种不同scale的图像后,在每一个scale,特征分布是不同的。之前的方法在UNet上面进行改进,直接的将不同scale的特征进行融合(skip connect)。如果把skip 拿开的话,一个decoder是基于low-reselution的featrue,对于noise的重构而言网络的base噪声分布是low-reselution的那个(8x8xC)的噪声特征。但是每个scale的噪声分布是不一样的,在这种网络得到的特征中没有做到scale分布独立。为了更好地重构出噪声分布,使用不同的decoder去基于不同scale的encoder得到特征去估计噪声分布会更好地提升网络的性能。整个网络可以看作,将不同scale的噪声分布重映射到原scale的空间中。然后将这些不同scale得到的噪声分布进行融合从而得到最后的噪声。 - 过度平滑的现象:
不同的patch的噪声强度也不同。尽管同一个scale的提取的噪声分布一样,但是强度不同,如果使用同样的卷积来对patch进行处理,对强噪声patch学到的filter,在处理弱纹理的patch时会丢失细节,而弱纹理的噪声强度本来就小,loss无法对这种情况进行约束。
本文提出使用多patch的方式来解决这个问题。
Method:
主要framework如下图所示。基于UNet,在每一个decoder的output后跟一个decoder卷到原size。
最后使用两个fusion 模块进行融合。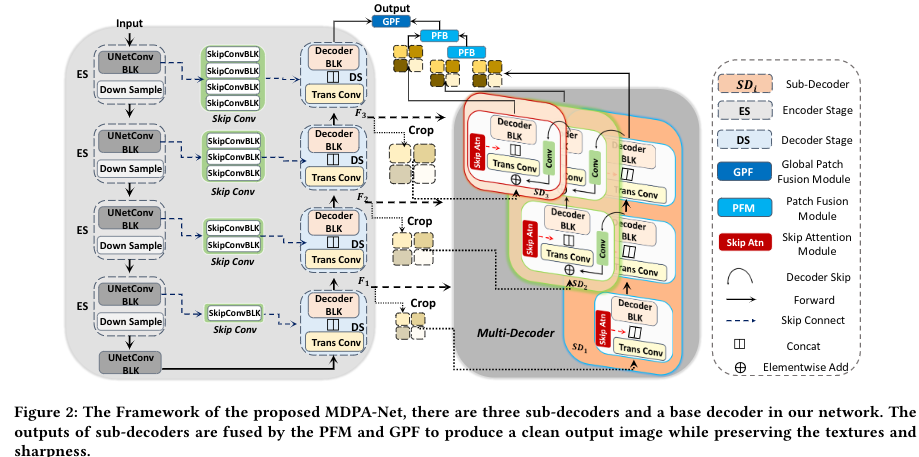
其中sub-decoder的细节: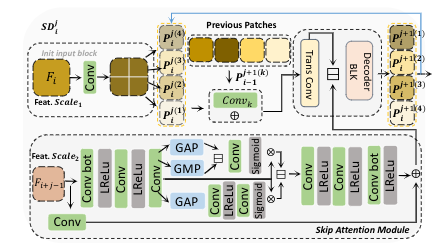
其中两个fusion module: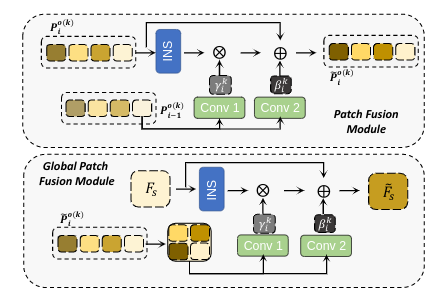
实验:
高斯生成噪声:
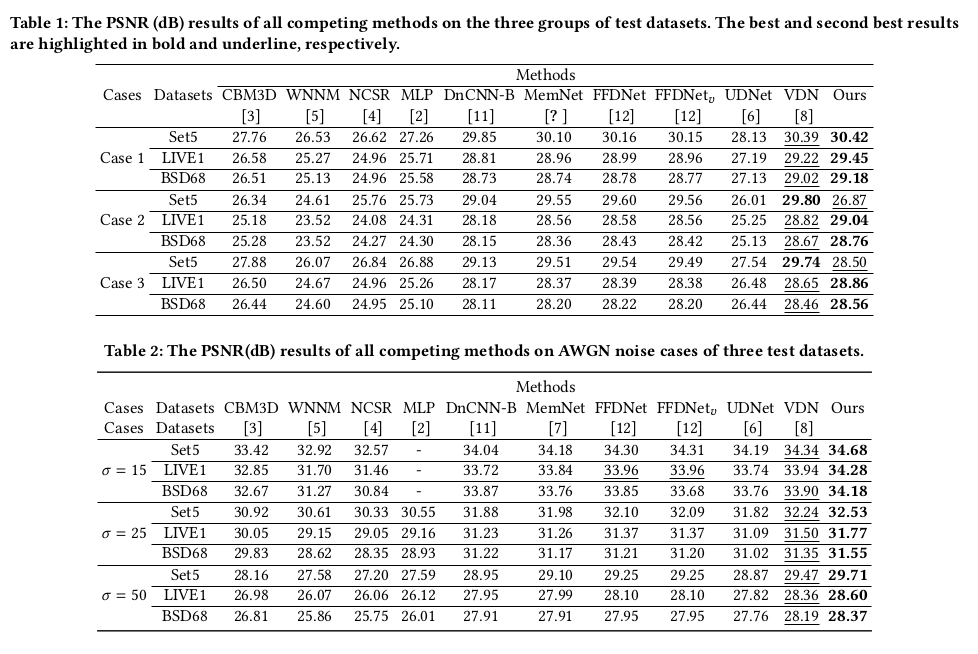
SIDD:

DND:

后面尝试了对齐的feature进行输入,具体地是用上一层的进行crop放在对应层,cat。上层特征,过skipattn 然后分块地与每一个块cat一起进行后续传播。文章提出的方法是:该层特征不分块,与每一个块cat一起后进行后续传播。
实际结果,方案一更好。
code
1 | def forward(self, ufeat, pre_stage_feats=None, ufeats=None): |