Coordinate Attention for Efficient Mobile Network Design
CVPR2021
Motivation:
Baseline: SE attention, CBAM
CBAM: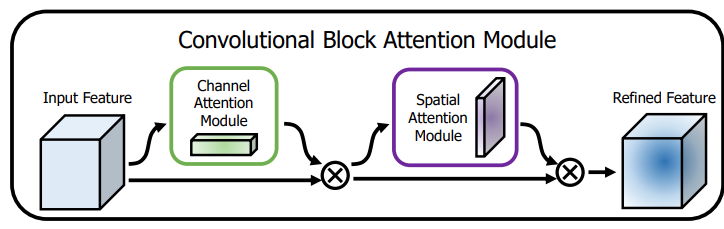
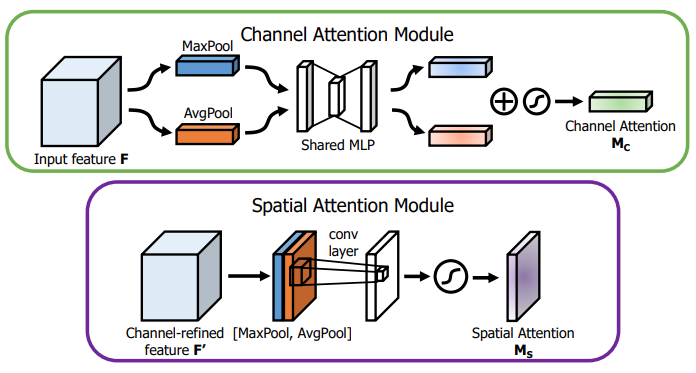
就是CA以及SA的结合attention。
Pipeline对比: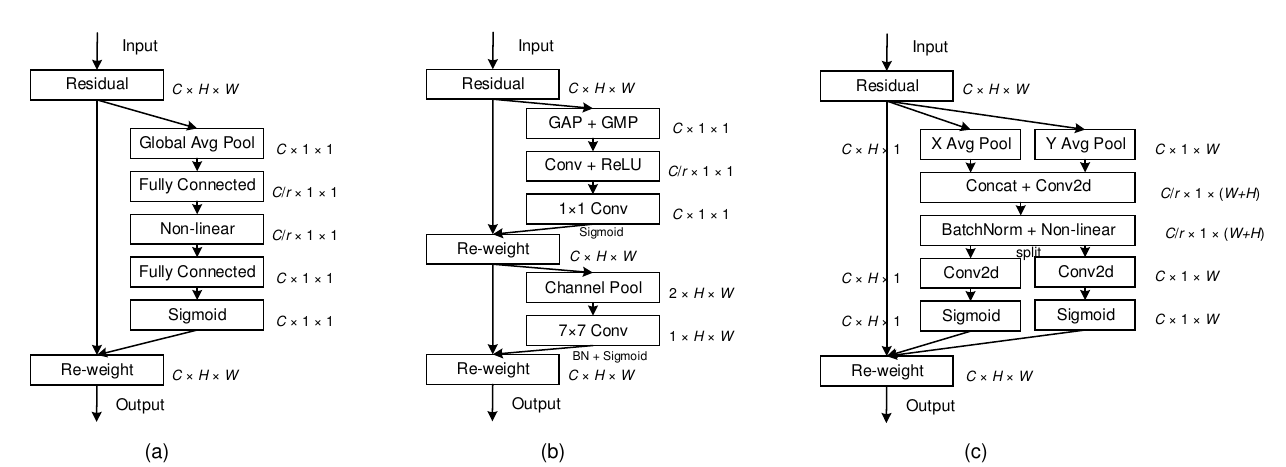
前面的两者都没有很好的考虑空间结构的相关性。
- SE 使用GAP将每一个通道化为一个标量,能保留全局信息,但是lack of 结构信息。
- CBAM 使用两个阶段来进行attention,一个是Channle-wise的也是同SE一样没有结构信息。另一个是Spatial Attention Module,这个模块将所有的channle 压缩到一个维度中,损失了部分信息。
- Coordinate attetnion: 在X,Y方向上做Pooling操作,这样一方面没有损失掉空间的信息,X 过Pool后可以用Y Pool的结果来弥补。也没有丢失整个Channle的信息。
Method:
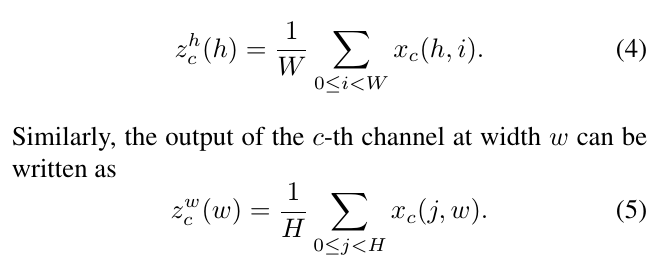
类比于SE中计算的整个单个Channle的均值或最大值,这里对feature $\mathbb{R}^{C \times H \times W}$ 进行对X轴、Y轴的均值计算,得到 $Z^w \in \mathbb{R}^{C \times 1 \times W} $ 和 $Z^h \in \mathbb{R}^{C \times H \times 1} $ 将这两个特征Cat起来经过Conv,进行BN和非线性激活: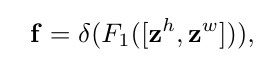
再split后,分别过两个Conv,其中 $F_h , F_w$ 是将 $f^h$ 通道数与input的feature一样。(之前Channle 有ratio)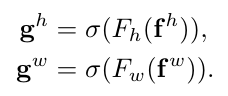
最后得到结合X,Y的方向信息的特征:
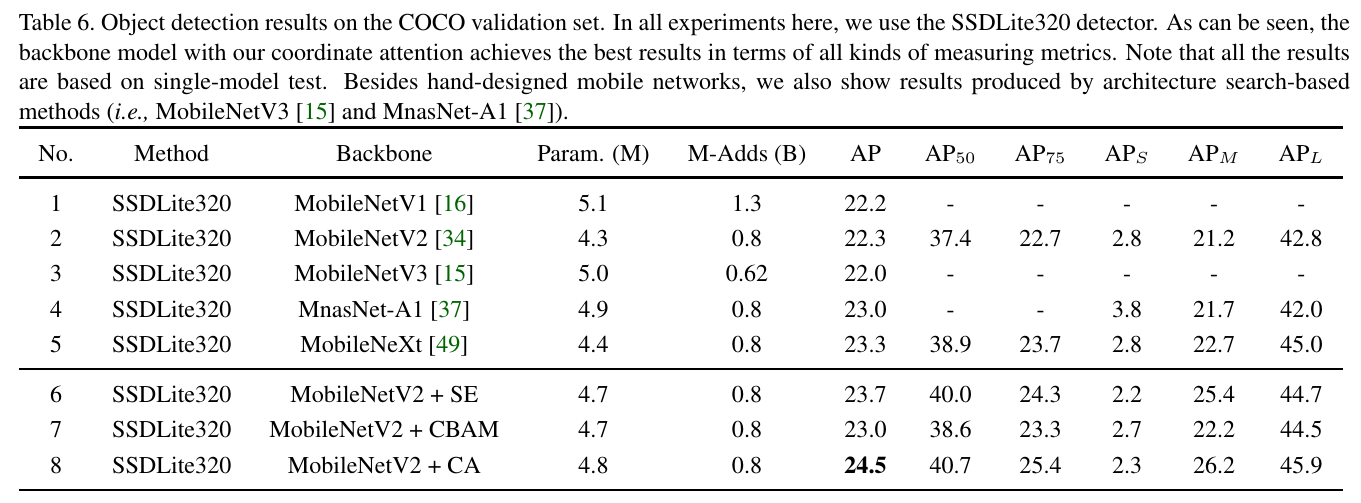
Results:
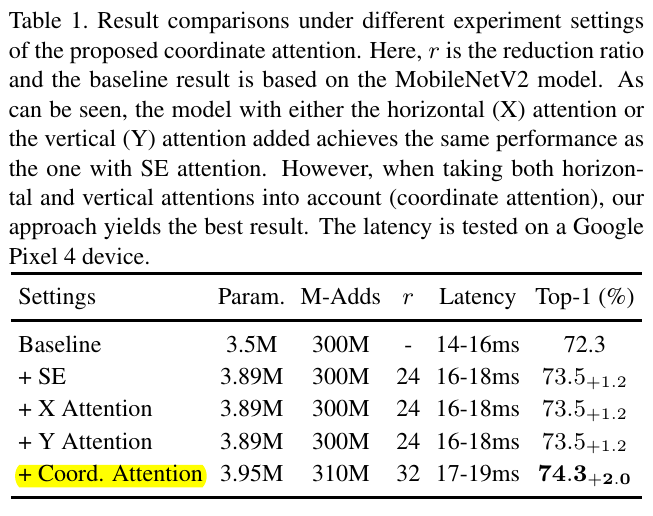
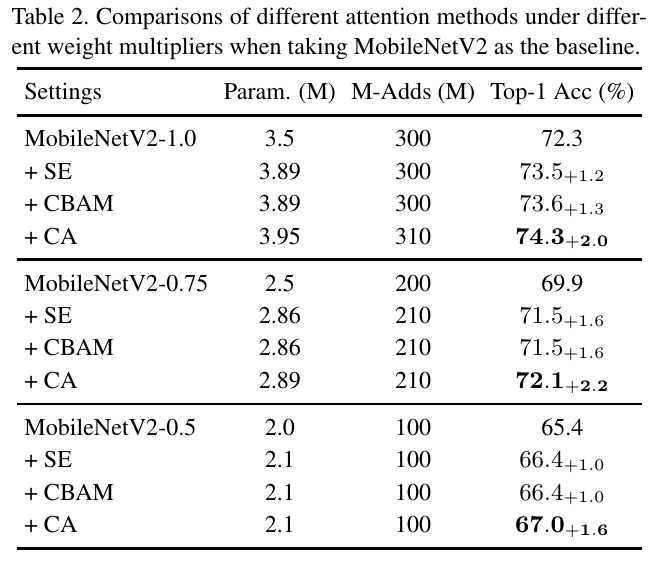
code
1 | class h_sigmoid(nn.Module): |