数据集组成
数据集含有1000个manipulate videos以及1000个源视频(FF++的youtube视频)
1000个manipulate 被5个等级的random-type distortions 处理,得到5个1000视频
1000个manipulate 使用more than one distortion处理,得到3个1000视频
文件分布:
- manipulate_video_list.txt中包含了11,000个manipulate视频
- endto_end_mix_distortions 是\数量的distortion方式得到的1000个视频。
- random_level是不同等级的,但是只有一种distortion.
standart set:
1,000 raw manipulated video and 1,000YouTube videos from FF++ form the standard set.
The videos are split into 7:1:2 as training, validation and test set.
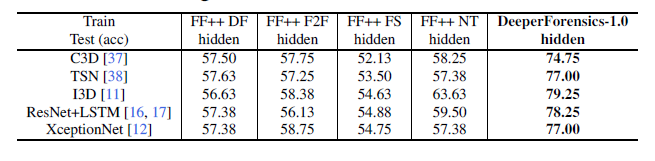
原文中的训练:
we use 1, 000 raw manipulated videos without distortions in the standard set of DeeperForensics-1.0. For FaceForensics++, the same split is applied to its four subsets.
实验一:
即使用下面5类进行训练得到模型。文中是在hidden set里面进行comp的,亦可以在test set中进行。
探讨了不同换脸方法对于模型performance的影响。
- 1,000 deeperF1.0 raw manipulate videos + 1,000 ori
- 1,000 Deepfake + 1,000 ori
- 1,000 Face2Fave + 1,000 ori
- 1,000 FaceSwap + 1,000
- 1,000 Nt + 1,000
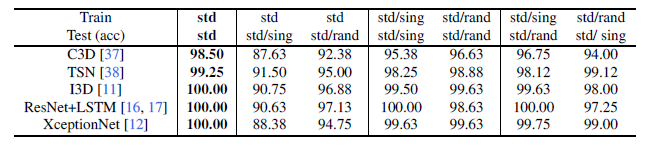
实验二
探讨dataset perturbations 对于模型performance的影响
We use 1, 000 manipulated videos in the standard set (std), 1,000 manipulated videos with single-level(level-5), random-type distortions (std/sing), 1,000 manipulatedvideos with random-level, random-type distortions (std/rand).
| 训练 | 测试 |
|---|---|
| std | std |
| std | std/sing |
| std | std/rand |
| std/sing | std/sing |
| std/rand | std/rand |
| std/sing | std/rand |
| std/rand | std/sing |
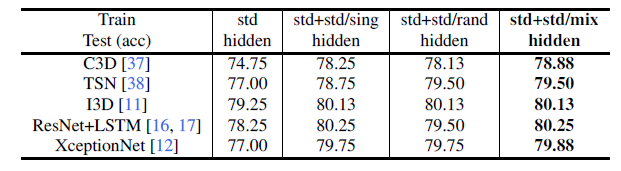
实验三
探讨训练集对于模型performance的影响
We use 1, 000 manipulated videos in the standard set (std), 1,000 manipulated videos with single-level(level-5), random-type distortions (std/sing), 1,000 manipulatedvideos with random-level, random-type distortions (std/rand).
we combine std with std/sing, std/rand, and std/mix, 其中std/mix是end_to_end_mix_3_distortions
| 训练 | 测试 |
|---|---|
| std | hidden |
| std + std/sing | hidden |
| std + std/rand | shidden |
| std+std/mix | hidden |