导言:在进行网络的训练过程中第一步就是要读入自己的数据集,在Pytorch中提供了Dataset\DataLoader来进行数据的读取。文章着重对自定义数据层得讲解,对源码进行了剖析。
Pytorch中DNN训练的数据模块主要是:
- 设置,初始化dataset加载数据
- 使用DataLoader对dataset的数据进行加载
Dataset
在datasets类中主要负责数据的读入,所以数据的增强以及数据的修建放在了这里。transform参数很好的体现了这一点。
封装好的dataset类:
在package:torchvision.datasets中提供了一些已经封装好的dataset类,这些类可以有:
ImageFolder每一个文件夹为一个类,加载后,同一个文件夹下的label是一致的。1
2
3
4
5
6
7
8
9
10data_transform = {x :transforms.Compose([transforms.Scale([64,64]),
transforms.ToTensor()
])
for x in ["train","valid"]
}
image_dataset = { x: torchvision.datasets.ImageFolder(
root = os.path.join(data_dir,x),transform = data_transform[x]
) for x in ["train","valid"]
}MNIST1
2
3
4
5
6data_train = datasets.MNIST(
root = "./data/",
transform = transform_,
train = True, #是训练集
download = False #使用本地的训练集
)
自定义Dataset类
参考博客
官方教程
自定义一个Dataset类必须需要一下三个函数
__init__(self)
初始化dataset主要就是数据的读入,从指定的路径读入什么数据,并且进行整理。最后整理成一个目标格式的块数据。__getitem__(self,index)
这个函数是当DataLoader对该数据集进行加载时执行的函数,每次获得一个数据项,如果有多个返回值那么load出来的也是多个列表(batch_size大小)__len__(self)
返回数据的总数
这里注意一个内存节约的问题
We will read the csv in
__init__but leave the reading of images to__getitem__. This is memory efficient because all the images are not stored in the memory at once but read as required.
在init中一般不建议将所有data全部读入,能之后读的就之后读。
如果想要在自定义dataset中和datasets中的类一样使用transform参数,则需要在init函数的参数中加入(transform)
最好在开头对Dataset的参数进行注释解释。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31class FaceLandmarksDataset(Dataset):
"""Face Landmarks dataset."""
def __init__(self, csv_file, root_dir, transform=None):
"""
Args:
csv_file (string): Path to the csv file with annotations.
root_dir (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied
on a sample.
"""
self.landmarks_frame = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.landmarks_frame)
def __getitem__(self, idx):
img_name = os.path.join(self.root_dir,
self.landmarks_frame.iloc[idx, 0])
image = io.imread(img_name)
landmarks = self.landmarks_frame.iloc[idx, 1:]
landmarks = np.array([landmarks])
landmarks = landmarks.astype('float').reshape(-1, 2)
sample = {'image': image, 'landmarks': landmarks}
if self.transform:
sample = self.transform(sample)
return sample
DataLoader
参考博客
官方教程
DataLoader是用来加载之前实例化好了的Dataset的函数,返回的是yield的对象,可以用来迭代输出。在DataLoader中注意有这些参数:
datasetbatch_sizeshuffle:每个epoch开始的时候,对数据进行重新排序sampler:自定义从数据集中取样本的策略函数,如果指定这个参数,那么shuffle必须为Falsebatch_sampler: 与sampler类似,但是一次只返回一个batch的indices(索引),需要注意的是,一旦指定了这个参数,那么batch_size,shuffle,sampler,drop_last就不能再制定了(互斥——Mutually exclusive)num_workers:这个参数决定了有几个进程来处理data_loading。0意味着所有的数据都会被load进主进程。(默认为0)关于dataloader中的worker_num可以参考这篇文章collate_fn:将一个list的sample组成一个mini-batch的函数pin_memory:如果设置为True,那么data loader将会在返回它们之前,将tensors拷贝到CUDA中的固定内存(CUDA pinned memory)中.drop_last:如果设置为True:这个是对最后的未完成的batch来说的,比如你的batch_size设置为64,而一个epoch只有100个样本,那么训练的时候后面的36个就被扔掉,如果为False(默认),那么会继续正常执行,只是最后的batch_size会小一点。worker_init_fn:每个worker初始化函数
我们先从整体来学习DataLoader的架构:下面是我精心作出的架构图: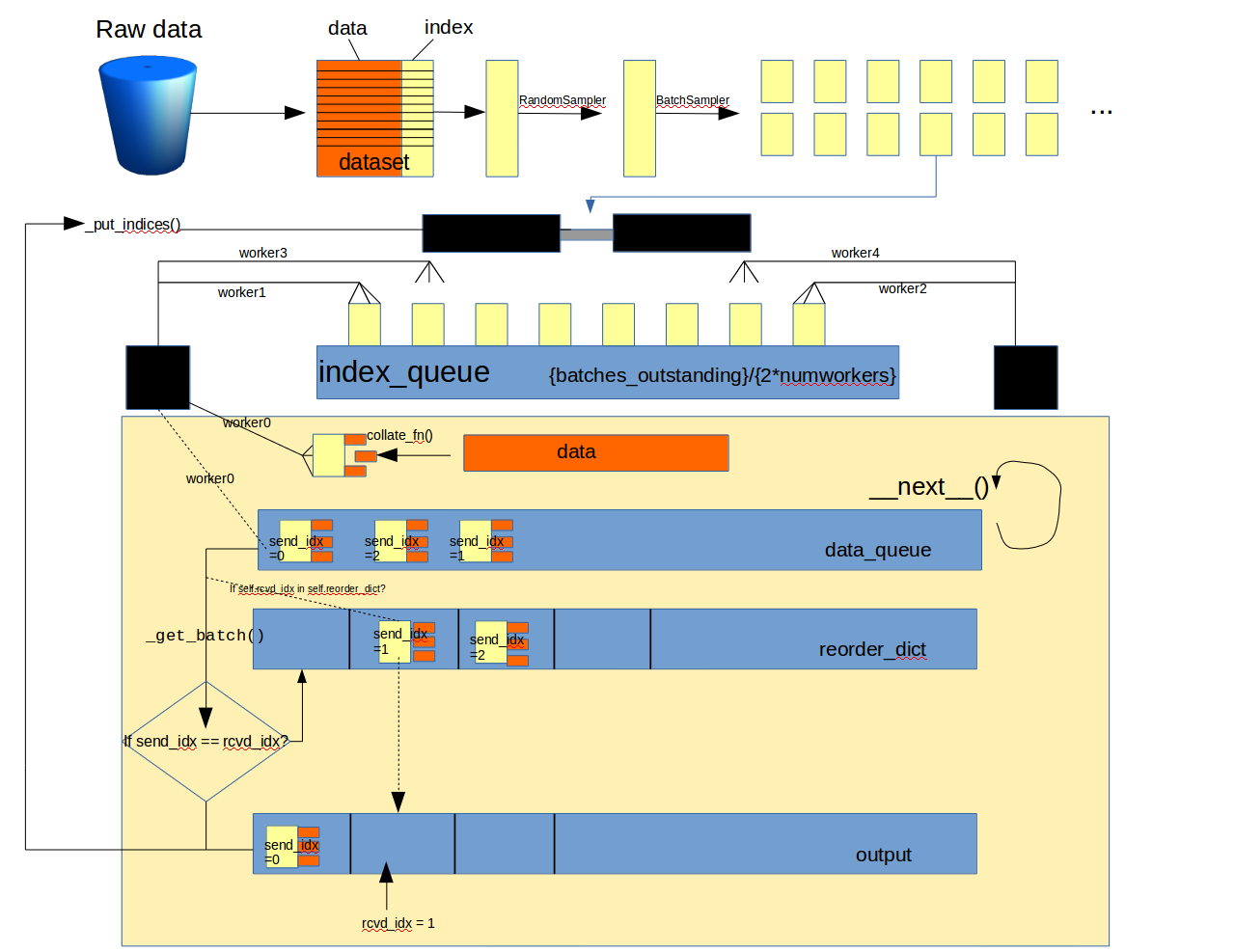
从图中我们可以清楚的直到Dataloader在干什么以及多进程是怎么发挥作用的。在这里需要指出的是只有当程序进行到collate_fn()时,数据才真正加载到内存中,而且仅是一个batch的数据。
data_queue这里装得都是数据,按照线程的整理顺序排列reorder_dict这里是一个字典,以顺序输出batchoutput最终的输出序列batches_outstanding是当前以及做好了的索引块的数量- 在
_DataLoader()中初始化的时候采取的是2倍numworkers数量的索引块,在__next()__中output一块后会再一次执行_put_indices()来提出索引块 worker依次将处理得到的数据放在data_queue中,这里是安装进程的先后顺序入队的- 每一次
__next()__都会取data_queue中出队的数据进行判断,如果正式当前所需要的(顺序正确=rcvd_idx)那么直接output,否则加入reorder_dict中等待下一次召集,很类似与计算机网络中的滑动窗口算法。
DataLoader的源码进行分析
1 | class DataLoader(object): |
可以看到在init函数中主要的就是几个抽样函数的运行:
RandomSampler():随机取样SequentialSampler()按顺序取样BatchSampler()按一个batch取出数据
注意iter必须返回一个迭代器(或者生成器)
单元取样函数
1 | import torch |
batch取样函数
根据前面取出的一个一个的数据进行组合,组合成一个batch的数据然后返回。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54class BatchSampler(Sampler):
r"""Wraps another sampler to yield a mini-batch of indices.
Args:
sampler (Sampler): Base sampler.
batch_size (int): Size of mini-batch.
drop_last (bool): If ``True``, the sampler will drop the last batch if
its size would be less than ``batch_size``
Example:
>>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False))
[[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]
>>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=True))
[[0, 1, 2], [3, 4, 5], [6, 7, 8]]
"""
def __init__(self, sampler, batch_size, drop_last):
if not isinstance(sampler, Sampler):
raise ValueError("sampler should be an instance of "
"torch.utils.data.Sampler, but got sampler={}"
.format(sampler))
if not isinstance(batch_size, int) or isinstance(batch_size, bool) or \
batch_size <= 0:
raise ValueError("batch_size should be a positive integeral value, "
"but got batch_size={}".format(batch_size))
if not isinstance(drop_last, bool):
raise ValueError("drop_last should be a boolean value, but got "
"drop_last={}".format(drop_last))
self.sampler = sampler
self.batch_size = batch_size
self.drop_last = drop_last
def __iter__(self):
batch = []
# 一旦达到batch_size的长度,说明batch被填满,就可以yield出去了
for idx in self.sampler:
batch.append(idx)
if len(batch) == self.batch_size:
yield batch
batch = []
if len(batch) > 0 and not self.drop_last:
yield batch
def __len__(self):
# 比如epoch有100个样本,batch_size选择为64,那么drop_last的结果为1,不drop_last的结果为2
if self.drop_last:
return len(self.sampler) // self.batch_size
else:
return (len(self.sampler) + self.batch_size - 1) // self.batch_size
if __name__ == "__main__":
print(list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False)))
# [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]
print(list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=True)))
# [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
比较灵活的就是iter()这里,每当满了batchsize个数就yield出去,yield是生成器,符合_iter的返回值规定(返回迭代器或生成器)。注意当最后如果遍历完整个sapler后如果batch不够batch_size,会根据不同的drop_last的值来进行操作。drop_last==True时会扔掉最后的一个batch
问题:数据是整个全部一下加载到内存中去吗?数据的加载流程是什么样的?
解答:在Dataset部分讲过数据中较大数据是放在__getitem__()中加载的(有一些数据会在init中直接加载完,但是对于几千张图片是不会在init中全部加载进去的。),以加载图像数据为例,__getitem__()是用来返回一个图像中的数据的,而调用这个函数是在dataloader中调用的,当dataloader在加载dataset时会执行他的2个sample函数(一个是单元、一个是batch)切记这里也并非是加载了真正的图像数据而是给了一个batch的作为index的随机数(序列数),然后通过__getitem__(self,index)依次取出对应的真实数据,所以并非是一下全部加载到内存中,而是一个batch一个batch的加载的
流程:
dataset初始化加载部分数据或不加载数据dataloader执行init获得随机indexdataloader调用_DataLoaderIter()使用多线程进行数据的读取
_DataLoaderIter
作用:从不同的index_queue中消费数据并将数据转换为data放入同一个data_queue中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109class _DataLoaderIter(object):
r"""Iterates once over the DataLoader's dataset, as specified by the sampler"""
def __init__(self, loader):
self.dataset = loader.dataset
# 将一个list的sample组成一个mini-batch的函数
self.collate_fn = loader.collate_fn
self.batch_sampler = loader.batch_sampler
self.num_workers = loader.num_workers
self.pin_memory = loader.pin_memory and torch.cuda.is_available()
self.timeout = loader.timeout
# 监听事件完成与否——https://www.cnblogs.com/lcchuguo/p/4687348.html
self.done_event = threading.Event()
# self.sample_iter是iterator:迭代器
self.sample_iter = iter(self.batch_sampler)
# 随机种子,用于worker_init_fn的初始化
base_seed = torch.LongTensor(1).random_().item()
if self.num_workers > 0:
# worker_init_fn是worker初始化函数
self.worker_init_fn = loader.worker_init_fn
# index_queue 索引队列 每个worker进程对应一个:
self.index_queues = [multiprocessing.Queue() for _ in range(self.num_workers)]
# worker 队列索引
self.worker_queue_idx = 0
# worker_result_queue 进程间通信
# multiprocessing.SimpleQueue是multiprocessing.Queue([maxsize])的简化,只有三个方法------empty(), get(), put()
self.worker_result_queue = multiprocessing.SimpleQueue()
# batches_outstanding
# 当前已经准备好的 batch 的数量(可能有些正在准备中)
# 当为 0 时, 说明, dataset 中已经没有剩余数据了。
# 初始值为 0, 在 self._put_indices() 中 +1,在 self.__next__ 中-1
self.batches_outstanding = 0
self.worker_pids_set = False
# shutdown为True是关闭worker
self.shutdown = False
# send_idx, rcvd_idx——发送索引,接收索引
# send_idx 用来记录 这次要放 index_queue 中 batch 的 idx
self.send_idx = 0
# rcvd_idx 用来记录 这次要从 data_queue 中取出 的 batch 的 idx
self.rcvd_idx = 0
# 因为多进程,可能会导致 data_queue 中的batch乱序
# 用这个来保证 batch 的返回是按照send_idx升序出去的。
self.reorder_dict = {}
# 创建num_workers个worker进程来处理
self.workers = [
multiprocessing.Process(
target = _worker_loop,
args = (self.dataset, self.index_queues[i],
self.worker_result_queue, self.collate_fn, base_seed + i,
self.worker_init_fn, i))
for i in range(self.num_workers)]
# 这里暂不分析CUDA或者timeout的情况
if self.pin_memory or self.timeout > 0:
self.data_queue = queue.Queue()
if self.pin_memory:
maybe_device_id = torch.cuda.current_device()
else:
# do not initialize cuda context if not necessary
maybe_device_id = None
self.worker_manager_thread = threading.Thread(
target=_worker_manager_loop,
args=(self.worker_result_queue, self.data_queue, self.done_event, self.pin_memory,
maybe_device_id))
self.worker_manager_thread.daemon = True
self.worker_manager_thread.start()
else:
# data_queue就是self.worker_result_queue(MultiProcessing.SimpleQueue()类型)
# 这个唯一的队列
self.data_queue = self.worker_result_queue
# 设置守护进程
for w in self.workers:
w.daemon = True # ensure that the worker exits on process exit
w.start()
_update_worker_pids(id(self), tuple(w.pid for w in self.workers))
_set_SIGCHLD_handler()
self.worker_pids_set = True
# prime the prefetch loop
# 初始化的时候,就将 2*num_workers 个 (batch_idx, sampler_indices) 放到 index_queue 队列中,防止进程一上来没有数据。
for _ in range(2 * self.num_workers):
self._put_indices()
def __len__(self):
...
def _get_batch(self):
...
def __next__(self):
...
def __iter__(self):
...
def _put_indices(self):
...
def _process_next_batch(self, batch):
...
如果想读懂_DataLoader使用多线程在干什么,那么必须要知道对于单个线程中_worker_loop()在干什么,以及multiprocessing类进行多进程操作,读懂上面的代码需要具备以下的知识:
- 什么是守护线程?多线程中守护线程
- 线程(进程)优先级队列队列操作以及信息的传递:菜鸟教程
- 多线程(进程)中event的作用
- join()方法是什么?join阻塞
一个josin的例子:1
2
3
4
5
6
7
8
9
10
11
12import os
import multiprocessing
def func():
print('son....PID:{}'.format(os.getppid()))
if __name__ == '__main__':
print('main process')
print('main is making son processes')
proc_1 = multiprocessing.Process(target = func)
proc_1.start()
#proc_1.join()
print('all done')
output:1
2
3
4main process
main is making son processes
all done
son....PID:2374
主进程运行结束后,子进程没有被销毁,依然运行直至结束。如果进程是为了配合主进程,这里就需要在子进程运行结束后,主进程才能退出,那这边就应该使用join的方法,join()的功能就是阻塞,当子进程运行时,pro_1.start()启动子进程,pro_1.join()阻塞,确保子进程运行结束才能运行其他进程
回过头来看workers1
2
3
4
5
6
7self.workers = [
multiprocessing.Process(
target = _worker_loop,
args = (self.dataset, self.index_queues[i],
self.worker_result_queue, self.collate_fn, base_seed + i,
self.worker_init_fn, i))
for i in range(self.num_workers)]
在这里new出来了num_workers个worker,然后我们再继续看每个进程做的事情。
1 | def _worker_loop(dataset, index_queue, data_queue, collate_fn, seed, init_fn, worker_id): |
感谢开源
特别感谢博客
ps:这篇博客的代码有些省略,配合官方源码看更好。