导言:在实验中发现对于归一化的理解不够到位,为此做一篇详解。
Pytorch中的BatchNorm1d():
这里将把一次训练过程进行剖析,获得其中的中间数据,然后展现BatchNorm的效果,BatchNorm的作用主要是防止数据在进入激活函数activation时其分部大多在未激活区,如ReLU的负数区域,sigmoid的趋近于1的区域,这些区域在计算梯度时都为0,无法达到后向传播的功能。并且如果核的权重初始化不正确(大概率),以ReLU为例:输入数据在第一层与核函数进行计算后,数据很可能有大部分处于负数区域,一旦数据处于负数区域,其激活值是0,那么之后的该点的激活值都是0,WX+B,B未正确初始化(大多为负数,这样WX=0+B必小于0),之后的所有ReLU层都会小于0,那样网络就死掉了,其他的激活函数类比ReLU。
所以大多时候如果我们的代码是正确的,但是老是train不起来,浅层的梯度很小或等于0,那么这时很有可能是我们的初始化不对,且没有进行BN。
这个情况很常见,在我之前train那篇东南大学的手势估计文章时(毕设)就没有考虑到这个问题,网络中的梯度流老是在0附近,并且我的代码应该是正确的,caffe训练本来就不需要什么代码。但是我没有使用pycaffe接口,没有对每一层进行权重的初始化,那么框架就会自动进行初始化,很可能我们的核权值就会让数据处于ReLU的负数区域,那么之后再怎么train都是徒劳的。
添加BN的位置也需要注意,input_data -> BN_for_data -> 核 -> BN -> action -> 核 -> BN -> action …
其位置是在进入激活函数之前,将上一个核函数计算得到的数据进行BN,然后输入进激活函数中。如果在激活函数之后,那么核产生的非激活数据仍然会进入核函数,其输出就是0,或者梯度回播就是0,那么之后再输入BN也无济于事。所以BN的位置是在核函数之后,激活函数之前
BN的对比图如下:
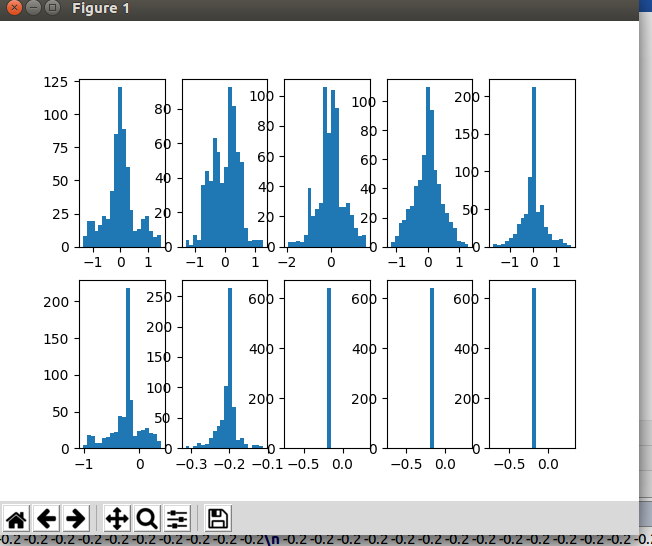
橘黄色的是有BN处理的,蓝色的是没有BN处理的。
1 | def forward(self,x): |
代码中的befAction 与 aftAction 只是记录了输入激活之前之后的x的数值,不是BN的位置,不要和之前的搞混了。
pytorch的forward函数即是前向计算的函数,可以将每一层的计算和联系体现出来。具体针对每一层的操作我目前想到的方法只是从layer.str来区分,是否存在其他方法可以直接提出层的属性?比如提出conv、pool、BN等类别?
可以在forward函数中做很多工作,在一个模型中的forward采取另一个模型进行forward也未尝不可。但是其backward会出现问题…这时题外话了,没有人会这样骚操作。
在Pytorch中
BatchNorm1d()的输入tensor.shape:- 输入:(N, C)或者(N, C, L)- 输出:(N, C)或者(N,C,L)(输入输出相同)在Pytorch中
BatchNorm2d()的输入tensor.shape:输入:(N, C,H, W)- 输出:(N, C, H, W)(输入输出相同)
注意这里说的输入不是搭建BN层时的输入,而是使用BN进行计算时的输入即:1
2bn = nn.BatchNorm2d(3)
x = bn(x)
此时x.shape() = n,c=3,h,w这一点核caffe是一样的
T20190819更新
上面直接说BN只是将输入得数据进行了归一化其实是不对的,在论文[Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift]中就说到:
Note that simply normalizing each input of a layer may change what the layer can represent. For instance, normalizing the inputs of a sigmoid would constrain them to the linear regime of the nonlinearity. To address this, we make sure that the transformation inserted in the network can represent the identity transform.
如果只做简单的归一化会破坏已经学到的特征分布,为了使得网络可以学到目标分布,作者要确保加入的这个BN变化要使得特征分布不会变更。
解决方案

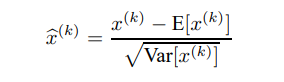
二每一个BN层需要学习的参数为:N*C*2